In 2017 publiceerde het World Wide Web Consortium (W3C) een standaard voor het valideren van graaf-data genaamd SHACL. SHACL staat voor “Shapes Constraint Language” en de naam geeft al een goede indicatie van wat het ondersteunt. SHACL is een taal (language) dat ons toelaat vormen (shapes) te voorschrijven waaraan een graaf aan moet voldoen. De vormen worden aan de hand van voorwaarden (constraints) beschreven. “Past” een (deel van een) graaf niet in de vorm, dan is deze niet geldig. SHACL biedt ons niet alleen een manier aan om dergelijke voorwaarden te beschrijven, een SHACL processor is nadien in staat om deze te verwerken en de controles uit te voeren.
SHACL valideert data, welke opgeslagen zijn als graaf-data in Resource Description Framework (RDF). RDF is net als SHACL een W3C standaard en een vaak onzichtbare gevestigde waarde om data te integreren. Details over RDF zijn voor dit artikel niet belangrijk, het volstaat te weten dat RDF een eenvoudig graaf-datamodel is en dat RDF ons toelaat “dingen” met International Resource Identifiers (IRI’s) te identificeren.[1] Een bekend voorbeeld van een IRI is een Uniform Resource Locator (URL) om een document op het Web te identificeren en op te vragen. Een IRI kan een verwijzing naar externe gegevens bevatten en hierdoor laat RDF ons toe om een gedistribueerde graaf te bouwen. We zullen zien dat SHACL de IRI’s gebruikt om naar fouten in de graaf-data te wijzen.
Omdat SHACL van RDF gebruik maakt, wordt het vaak in de context van Linked Data voorgesteld. Desalniettemin is het beeld van SHACL wat genuanceerder; SHACL werd ontwikkeld om RDF graaf-data te valideren, ongeacht het Linked Data is. Door deze nuance in het achterhoofd te houden, wordt het makkelijker om opportuniteiten en cases te vinden. Dit artikel poogt deze nuance, aan de hand van voorbeelden, te belichten.
Een scenario als motivatie
Als gegevens uit verschillende systemen dienen gecombineerd te worden, dan moet men rekening houden met voorwaarden die over die systemen heen gelden. Omdat elk systeem normaliter enkel verantwoordelijk is voor de data die tot hun scope behoren, worden die voorwaarden niet door de afzonderlijke systemen afgetoetst. Het valideren van die voorwaarden is echter belangrijk om de kwaliteit van de gegevens in zijn geheel te vrijwaren.
We illustreren de problematiek met een eenvoudig voorbeeld. We hebben een aangiftesysteem (Systeem A) en een systeem voor het distribueren van voordelen (Systeem B). Elk systeem heeft een conceptueel schema waaruit delen van de applicatielaag en een database schema voortvloeien (zie onderstaand figuur).
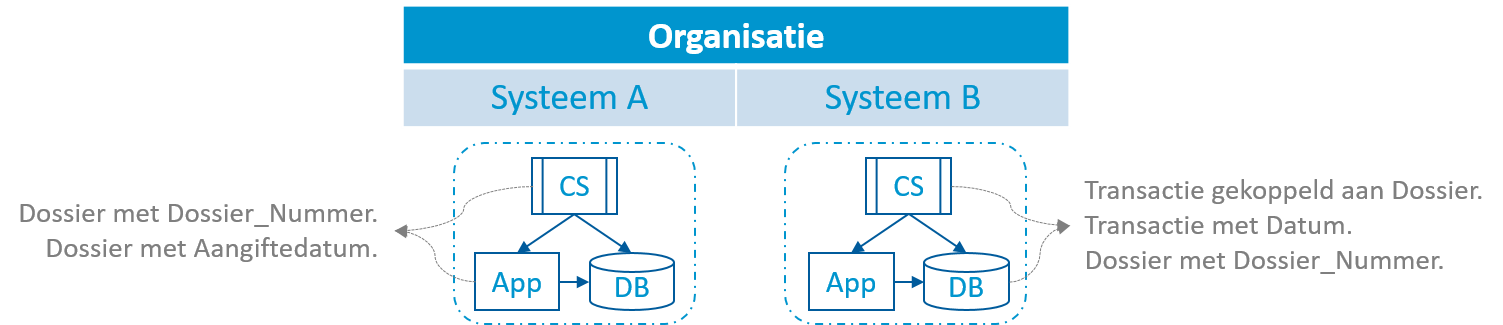
Twee autonome systemen met gemeenschappelijke concepten. Elke systeem is verantwoordelijk voor de correcte opslag van hun data, doch gelden er voorwaarden over systemen heen. De systemen die nu bestaan kunnen deze echter niet aftoetsen.
Beide systemen delen concepten, in dit geval de concepten “dossier” en “dossiernummer”. Systeem B houdt de data van transacties bij, waaronder een verwijzing naar het dossier van een transactie. Systeem B hoeft de datum van aangifte niet bij te houden omdat dit niet tot de scope van het systeem behoort. Doch is het logisch dat, alvorens het tweede systeem een transactie kan uitvoeren (in dit geval het toewijzen van een voordeel), dat de datum van aangifte vóór eender welke transactie moet liggen. Men gaat er van uit dat alles binnen een organisatie vlot verloopt en er dus geen problemen zijn. Maar hoe controleren we dit?
Men kan controlescripts schrijven die de verschillende bronnen raadplegen, maar dan zitten de voorwaarden “verborgen” in de code van die scripts. Is er een manier om die voorwaarden “buiten” de systemen op een gestructureerde en transparante manier te beschrijven? Ja, SHACL biedt een oplossing op die vraag. Vooraleer we dit demonstreren, zullen we SHACL eerst toelichten.
SHACL
SHACL biedt ons een nieuwe manier om data op een open, gestructureerde, en transparante wijze te valideren. SHACL laat ons toe om voorwaarden aan de hand van open en gestandaardiseerde modellen buiten de eigenlijke programmatie te definiëren en te valideren. Omdat SHACL expressiever is dan de meeste databasetechnologieën, maakt SHACL complexe logische- en vormcontroles mogelijk.
We hebben reeds aangehaald dat SHACL RDF grafen valideert. De graaf die wordt gevalideerd wordt de data graph genoemd. De shapes graph bevat de voorwaarden beschreven met SHACL en wordt ook als een RDF graaf opgeslagen. De data graph en shapes graph worden door een validatieproces verwerkt en als resultaat hebben we een validation report. Het rapport is een RDF graaf met het resultaat: de data graph is conform of niet. Indien niet conform, dan bevat het rapport een lijst van problemen met gedetailleerde informatie en verwijzingen naar problemen.
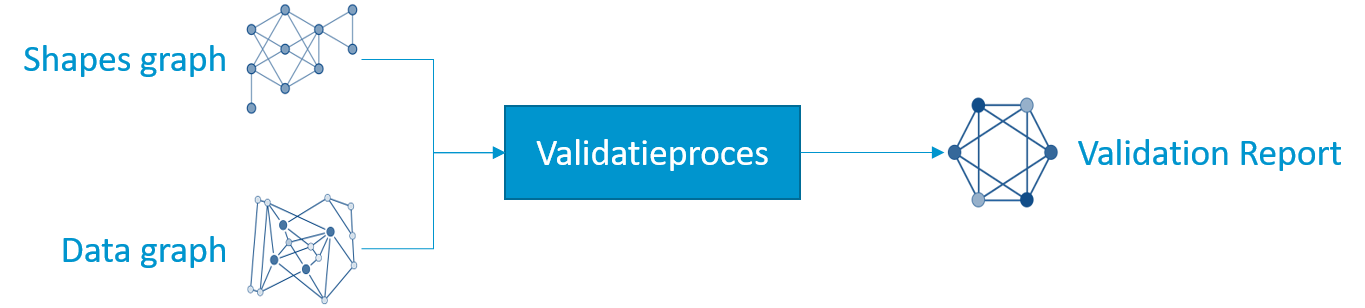
Een SHACL validatieproces maakt gebruik van een shapes graph om de data graph te valideren. Dit resulteert in een validatierapport dat ook als een graaf wordt opgeslagen. Het rapport verwijst naar de problemen dankzij IRI’s en RDF.
De shapes graph bevat een verzameling shapes waaraan de data graph moet voldoen. Het proces verloopt in drie stappen. Voor elke shape S in de shapes graph gaat het proces:
- Op zoek naar de zogenaamde focus nodes in de data graph. Elke shape definieert de focus nodes aan de hand van “targets”. Een shape voor transacties heeft als target “alle entiteiten van het type Transactie”, bijvoorbeeld. Deze stap geeft een verzameling terug.
- Voor elk element in de verzameling focus nodes worden alle voorwaarden in de shape S afgetoetst. Elk probleem wordt aan een lijst toegevoegd. Voorbeelden van zulke voorwaarden zijn:
- Elke transactie behoort tot exact één dossier;
- De datum van een transactie moet groter zijn dan de datum van aangifte van het dossier dat tot die transactie behoort;
- …
- De lijst van problemen wordt gebruikt om een validatierapport op te maken.
Hoewel men spreekt van een data- en shapes graph, hoeven deze graphs niet afzonderlijk bewaard te worden. Men kan de twee grafen in één grote (kennis)graaf opslaan. SHACL en het validatieproces zijn intelligent genoeg om de shapes uit de graaf te extraheren.
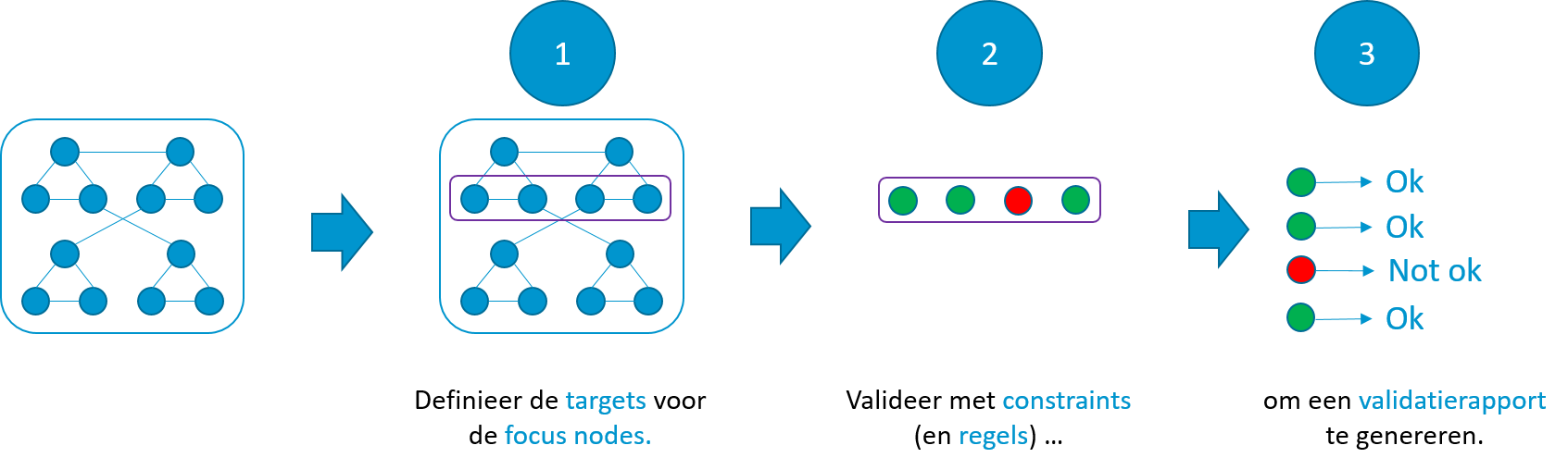
Stappen in het validatieproces
Demonstratie
We zullen SHACL nu aan de hand van eenvoudig voorbeeld illustreren. We vertrekken van ons inleidend scenario en gaan er van uit dat onze gegevens reeds in een RDF graaf werden geïntegreerd. We zullen eerst nagaan of dossiers exact één datum van aangifte hebben. Onze data graph ziet er als volgt uit:
1. @prefix ex: <http://www.example.com/ns#> .
2. @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
3.
4. ex:D1
5. a ex:Dossier ;
6. .
7.
8. ex:D2
9. a ex:Dossier ;
10. ex:ingediendOp "2021-02-20" ;
11. .
12.
13. ex:D3
14. a ex:Dossier ;
15. ex:ingediendOp "2021-02-21"^^xsd:date ;
16. .
Hier hebben we informatie over drie dossiers (ex:D1, ex:D2, en ex:D3). D1 heeft geen datum, D2 heeft een datum van het type string (default datatype), en D3 heeft een datum van het type datum. De graaf bevat verder (nog) niets. In onze shapes graph beschrijven we de voorwaarden voor een geldig dossier:
1. @prefix ex: <http://www.example.com/ns#> .
2. @prefix sh: <http://www.w3.org/ns/shacl#> .
3. @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
4.
5. ex:DossierShape
6. a sh:NodeShape ;
7. sh:targetClass ex:Dossier ;
8. sh:property [
9. sh:path ex:ingediendOp ;
10. sh:datatype xsd:date ;
11. sh:minCount 1 ;
12. sh:maxCount 1 ;
13. ] ;
14. .
Op lijn 5 declareren we een nieuwe shape voor Dossiers. Deze shape gaat enkel entiteiten van het type Dossier valideren (lijn 7). In deze shape worden er voorwaarden op de relatie (property) ex:ingediendOp gedeclareerd. De voorwaarden voor deze relatie zijn:
- van het type xsd:date (lijn 10),
- minimaal één (lijn 11), en
- maximaal één (lijn 12).[2]
Eens we de data graph en de shapes graph als input aan een SHACL processor geven, dan krijgen we het volgende validatierapport:
$ pyshacl -s shacl.ttl -m -f human data.ttl
Validation Report
Conforms: False
Results (2):
Constraint Violation in DatatypeConstraintComponent (http://www.w3.org/ns/shacl#DatatypeConstraintComponent):
Severity: sh:Violation
Focus Node: ex:D2
Value Node: Literal("2021-02-20")
Result Path: ex:ingediendOp
Message: Value is not Literal with datatype xsd:date
Constraint Violation in MinCountConstraintComponent (http://www.w3.org/ns/shacl#MinCountConstraintComponent):
Severity: sh:Violation
Focus Node: ex:D1
Result Path: ex:ingediendOp
Message: Less than 1 values on ex:D1->ex:ingediendOp
Dit rapport werd gegenereerd met pySHACL (later verwijzen we naar andere implementaties). Deze implementatie biedt ons, voor de demonstratie, een vrij leesbaar rapport in een console omgeving. Men kan zien dat twee dossiers niet aan de voorwaarde voldoen. Het rapport bevat verder expliciete verwijzingen naar de problemen.
We breiden het voorbeeld uit met transacties. We nemen aan dat transacties een datum hebben. De datum van een transactie moet, in principe, groter zijn dan de aangiftedatum van het dossier van die transactie. Voor de tweede demonstratie gebruiken we de volgende data graph:
1. @prefix ex: <http://www.example.com/ns#> .
2. @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
3.
4. ex:D3
5. a ex:Dossier ;
6. ex:ingediendOp "2021-02-21"^^xsd:date ;
7. .
8.
9. ex:T1
10. a ex:Transactie ;
11. ex:behoortTot ex:D3 ;
12. ex:geregistreerdOp "2021-02-22"^^ex:date ;
13. .
14.
15. ex:T2
16. a ex:Transactie ;
17. ex:behoortTot ex:D3 ;
18. ex:geregistreerdOp "2021-02-21"^^ex:date ;
19. .
We behouden dossier ex:D3 en voegen twee transacties ex:T1 en ex:T2 toe. Beide transacties behoren tot Dossier ex:D3. Merk op dat de registratiedatum van ex:T2 en de aangiftedatum van ex:D3 op dezelfde dag vallen. Dit zou niet mogen. Gelukkig kunnen we nu de voorwaarde op de geïntegreerde data aftoetsen. We maken een shape voor transacties die dit zal controleren:
1. @prefix ex: <http://www.example.com/ns#> .
2. @prefix sh: <http://www.w3.org/ns/shacl#> .
3. @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
4.
5. # ex:DossierShape hier
6.
7. ex:TransactieShape
8. a sh:NodeShape ;
9. sh:targetClass ex:Transactie ;
10. sh:property [
11. sh:path ex:behoortTot ;
12. sh:class ex:Dossier ;
13. sh:minCount 1 ;
14. sh:maxCount 1 ;
15. ] ;
16. sh:property [
17. sh:path ( ex:behoortTot ex:ingediendOp ) ;
18. sh:lessThan ex:geregistreerdOp ;
19. ] ;
20. .
We laten de kardinaliteit en data type van de registratiedatum even buiten beschouwing (deze voorwaarden lijken op het vorige voorbeeld). Op lijnen 10 tot en met 15 controleren of elke transactie tot exact één entiteit van het type Dossier behoort. Op lijnen 16 tot en met 19 vergelijken we twee waarden: de aangiftedatum van het dossier via een complex pad (“ingediend op” via “behoort tot”) en de registratiedatum. Het validatieproces geeft ons het volgend rapport:
$ pyshacl -s shacl.ttl -m -f human data.ttl
Validation Report
Conforms: False
Results (1):
Constraint Violation in LessThanConstraintComponent (http://www.w3.org/ns/shacl#LessThanConstraintComponent):
Severity: sh:Violation
Focus Node: ex:T2
Value Node: Literal("2021-02-21", datatype=xsd:date)
Result Path: ( ex:behoortTot ex:ingediendOp )
Message: Value of ex:T2->ex:geregistreerdOp <= Literal("2021-02-21", datatype=xsd:date)
De transactie ex:T1 is correct en komt dus niet in het rapport voor. De node ex:T2 heeft echter een fout. Het rapport geeft aan dat de waarde van het pad niet kleiner is dan de waarde voor ex:geregistreerdOp. De boodschap van de fout leest dat de waarde van ex:geregistreerdOp kleiner of gelijk is aan de waarde van het pad.
Bovenstaand voorbeeld met samengestelde paden licht maar het tipje van de sluier met betrekking tot SHACL’s mogelijkheden. SHACL ondersteunt de combinatie van voorwaarden aan de hand van logische operatoren (and, or, not, …) en bevat een belangrijk aantal ingebouwde functies voor onder andere tekenreeksen, numerieke gegevens, en data. SHACL biedt verder ook ondersteuning voor het aanmaken van (domein-specifieke) voorwaarden. Dergelijke voorwaarden worden beschreven in SPARQL (de querytaal voor RDF grafen) die in constraint components worden ingekapseld. Omdat die op maat gemaakte voorwaarden in RDF beschreven worden, kunnen deze dan ook op verscheidene plaatsen worden bevraagd en hergebruikt. Met andere woorden: onze op maat gemaakte voorwaarden zijn zelf interoperabel.
Standaard is de ernst van alle problemen een “overtreding” (violation)–een kritisch probleem. Men kan echter de ernst van bepaalde voorwaarden aanpassen naar een “waarschuwing” (warning) en “informatie” (info) voor niet-kritische problemen. Dit verandert niets aan het validatieproces en het is dus aan een volgend proces om deze te interpreteren. We kunnen problemen prioriteren, bijvoorbeeld.
Mogelijkheden en implementaties
SHACL is een open standaard en hierdoor hebben we toegang tot verschillende implementaties, zowel vrij als commercieel. Voorbeelden van open en vrije implementaties zijn Apache Jena, TopBraid SHACL API, en pySHACL. Apache Jena ondersteunt de basis van SHACL. TopBraid SHACL API (gebouwd bovenop Apache Jena) en pySHACL ondersteunen een deel van de “advanced features” (SHACL-AF) zoals geavanceerde afleidingsregels en functies. SHACL-AF werd nog niet gestandardiseerd en behoort dus niet tot de basisspecificatie. Interessant om weten is dat TopQuadrant (het bedrijf achter TopBraid SHACL API) bij de standaardisatie betrokken is. Men ziet tegenwoordig ook dat commerciële oplossingen SHACL ondersteunen. Neo4j’s graph database, bijvoorbeeld, voegt de ondersteuning van SHACL incrementeel aan hun suite toe.
SHACL wordt niet alleen opslagen in RDF grafen, maar wordt ook toegepast op RDF grafen. Dit brengt een aantal voordelen en mogelijkheden met zich mee:
- SHACL bevordert transparantie. De shapes graph en validatierapporten zijn onderdeel van de kennis die men binnen een organisatie deelt. We kunnen beiden dus als onderdeel van een kennisgraaf beschouwen en de SHACL voorwaarden bevragen aan de hand van graph query-talen. Hierdoor heeft men een holistisch beeld van welke gegevens er bestaan in de kennisgraaf, hoe deze er dienen uit te zien, en hoe deze dienen te worden gebruikt.
- Men kan SHACL shapes annoteren met metadata. Dit is mogelijk dankzij de RDF graaftechnologie waarmee SHACL is onderbouwd. We kunnen, voor elk onderdeel van de shapes graph, aanduiden vanwaar de voorwaarde komt, de rationale, waar documentatie gevonden kan worden, etc. Eens dergelijke informatie voorhanden is, dan kan een organisatie op een homogene manier de informatie bevragen. Bevragingen (i.e., queries) zoals “welke voorwaarden gelden omtrent het concept Dossier en vanwaar komen deze?” zijn dan eenvoudig te realiseren.
- SHACL kan op verschillende plaatsen en op verschillende manieren toegepast worden: ter validatie van een kennisgraaf in zijn geheel, ter validatie van inputgegevens alvorens deze te integreren, en ter validatie van gegevens die dienen gedeeld te worden.
- Als laatste hebben we de actieve community en werkgroep achter SHACL. SHACL zelf bestaat reeds een aantal jaren. De community, gedreven door een belangrijk aantal industriepartners, is actief en werkt aan uitbreidingen voor taken naast validatie, zoals het genereren van interfaces en het begeleiden van zoekopdrachten. De kans bestaat dat men dra dergelijke tools kan gebruiken of uitproberen.
Nadelen
Hoewel SHACL ons toelaat voorwaarden buiten een systeem te externaliseren op een open en gestandaardiseerde wijze, moet men ook een aantal mogelijke nadelen overwegen.
- Ten eerste maakt SHACL gebruik van RDF als graaf-datamodel. Hoewel SHACL best expressief is, dienen sommige voorwaarden in SPARQL geformuleerd te worden. De nodige expertise in RDF, SPARQL,… dient in een organisatie aanwezig te zijn of opgebouwd te worden, wat niet per se evident is.
- Ten tweede kan SHACL complex overkomen. Complexe voorwaarden blijven complex, ongeacht de taal of omgeving. Maar wanneer deze complexiteit wordt gecombineerd met een gebrek aan RDF expertise, dan kan de leercurve steil zijn. Verder werd de standaard intentioneel compact gehouden. SHACL biedt de vergelijkingsoperatoren “kleiner dan” en “kleiner dan of gelijk aan” aan, maar niet de inverse operatoren. Indien men nood heeft aan de inverse relaties, dan moet men de shapes herschrijven (e.g., aan de hand van de beschikbare logische operatoren) of zelf de voorwaarden maken.
- Als derde puntje hebben we de beperkingen van bepaalde implementaties. De meeste bibliotheken werken op gematerialiseerde grafen. Dit wil zeggen dat de grafen in een RDF bestand of een RDF graafdatabase werden openslagen. Komt de data van andere bronnen zoals een relationele databank, dan brengt dit uitdagingen wat betreft dataduplicatie en latency met zich mee. Dataduplicatie spreekt voor zich; we hebben “dezelfde” data op twee verschillende locaties. Het is bijgevolg mogelijk dat onze validatierapporten ten opzichte van de originele databronnen gedateerd zijn (i.e., latency). Er zijn initiatieven om databronnen als virtuele (kennis)grafen te benaderen, en dit is het onderwerp van een volgend artikel.
Andere motiverende scenario’s
In deze tekst legden we de nadruk op gegevens over systemen heen die, eens geïntegreerd, dienden gecontroleerd te worden. De toepassing van SHACL in deze context had dus betrekking op gegevensbeheer en gegevenskwaliteit. Hier zullen we het even hebben over andere motiverende scenario’s voor SHACL.
Ten eerste hebben we voorwaarden “verborgen” in code. Het gebeurt vaak dat bepaalde voorwaarden , die wel in het conceptueel model beschreven worden (bijvoorbeeld met UML-notatie), niet door de onderliggende databasetechnologieën worden ondersteund. Hierdoor zijn deze voorwaarden dan verborgen in de applicatielaag (i.e., de code). Belanghebbenden die de database onder de loep nemen zijn dan niet noodzakelijk op de hoogte van de voorwaarden die op een hoger niveau werden beschreven. Daar applicaties vaak evolueren, kan het de moeite lonen om die voorwaarden buiten het systeem op een open, herbruikbare, en transparante manier te declareren om de kwaliteit van de data te vrijwaren.
SHACL laat ook ons toe om inputgegevens, e.g., van formulieren, te valideren alvorens deze te integreren. Men kan twee complementaire benaderingen observeren. De logische- en vormcontroles van opzichzelfstaande inputgegevens alvorens deze te integreren, en de controles van de inputgegevens samen met de rest van data alvorens deze te integreren. In de tweede benadering is de data graph de unie van de inputgegevens en de data.
Als laatste hebben we gegevensuitwisseling, ofte semantische interoperabiliteit. Gegevensuitwisseling is een derde scenario en een vervolg van het tweede. In dit geval representeert SHACL de verwachtingen van, en afspraken tussen, de betrokken partijen. Omdat SHACL de voorwaarden als RDF opslaat, kan men deze voorwaarden centraliseren, ter beschikking stellen, en bevragen. Dit is makkelijk te realiseren door de shapes een IRI te geven die men kan consulteren (e.g., een URL binnen een bedrijfsnetwerk).
Conclusies
SHACL laat ons toe om graafdata op een flexibele en expressieve wijze te valideren. Hoewel SHACL initieel complex is en kennis van RDF technologieën vereist, is SHACL een mogelijks waardevolle aanvulling om de kwaliteit van data te bewaken. Een mogelijke use case is om de data van verschillende bronnen in een graaf te integreren om dan daarop voorwaarden over systemen heen te valideren. Verder is SHACL een open standaard met bestaande tooling. Er bestaan vrije bibliotheken om met SHACL aan de slag te gaan. Verder wordt SHACL ook in bredere semantische oplossingen (zoals de producten van TopQuadrant en Poolparty) geïntegreerd. Bestaande bibliotheken vertrekken doorgaans van gematerialiseerde grafen (i.e., dataduplicatie). Als dit een probleem zou vormen, dan kan men virtuele knowledge graphs onder de loep nemen. Virtual knowledge graphs staan ook in 2021 op de radar van Smals Research.
Voetnoten
[1] RDF is een onderwerp dat we in een eerdere blog post hebben behandeld. RDF beschrijft dingen aan de hand van zogenaamde triples. Triples zijn van de vorm (subject, predicate, object) en verbinden een onderwerp (subject) met een voorwerp (object) aan de hand van een relatie (predicate). Een voorbeeld hiervan is: ex:Christophe ex:werkt_voor ex:SmalsResearch.
[2] De combinatie van “minimaal één” en “maximaal één” leidt tot “exact één”. SHACL heeft, om de standaard niet te ingewikkeld te maken, bewust voor een beperkt aantal voorwaarden gekozen. SHACL biedt wel de mogelijkheid om eigen voorwaarden aan te maken.
_________________________
Dit is een ingezonden bijdrage van Christophe Debruyne, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply