Tools voor confidential computing

In een vorig artikel gaven we een algemeen overzicht van TEE’s en het nut ervan. In dit artikel gaan we dieper in op hoe de belangrijkste commerciële implementaties werken. Continue reading
In een vorig artikel gaven we een algemeen overzicht van TEE’s en het nut ervan. In dit artikel gaan we dieper in op hoe de belangrijkste commerciële implementaties werken. Continue reading
Dans un article précédent, nous avons présenté de manière générale ce qu’étaient les TEE et leur utilité. Dans cet article nous regardons plus en détail le fonctionnement des principales mises en œuvre commerciales. Continue reading

Dans un article précédent, nous avons dressé la liste des opportunités d’améliorations de l’assistance à
la clientèle. Les centres de contact sont soumis à une pression constante de répondre aux questions le
plus efficacement possible. Dans cet article, nous examinons de plus près l’une des techniques
possibles : le routage vocal. Continue reading

Naar aanleiding van de lancering van ChatGPT duiken er massaal tools op die toelaten om vragen te beantwoorden over je eigen content. Het wordt heel eenvoudig voorgesteld: upload je documenten (PDF, Word, etc.) en je kan quasi onmiddellijk vragen beginnen stellen, typisch in een chatbot-achtige omgeving.
In dit artikel geven we aan hoe zo’n question answering systeem in elkaar steekt en vertellen we wat meer over de kwaliteit die we kunnen verwachten van de output. Continue reading
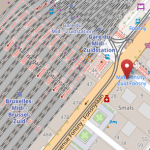
Om een adres te kunnen plaatsen op een kaart, om een reisweg uit te stippelen of om alle winkels in een bepaalde wijk te bepalen, moet er eerst een belangrijke stap genomen worden: geocodering. Deze handeling houdt in dat een postadres zoals “Av. Fonsny 20, 1060 Bruxelles” enerzijds “gestandaardiseerd” kan worden (bordeaux gedeelte van onderstaande afbeelding), en anderzijds dat deze geografische coördinaten toegewezen krijgt (“location” in de afbeelding). Continue reading

Dans un blog précédent, nous avions introduit l’initiative prise par Smals Recherche en collaboration avec les analystes business d’organiser des ateliers dans le but de capturer les opportunités d’intelligence artificielle (IA) chez nos membres. Pour rappel, l’objectif de ces ateliers … Continue reading

De plus en plus de données personnelles sensibles sont stockées sous forme numérique,tandis que les cyberattaques deviennent de plus en plus avancées. Aussi l’amélioration de la protection des données à caractère personnel fait-elle l’objet d’une attention de tous les instants. Continue reading

De kwaliteit van een gegeven is de geschiktheid ervan voor gebruik en voor de beoogde doelstellingen (‘fitness for use’) (Boydens, 1999, Boydens 2014). In dit artikel gaan we bekijken hoe een rigoureuze typologie van de anomalieën een kader biedt voor de verbetering van de kwaliteit van de gegevens, in verschillende domeinen, waaronder machine learning. Continue reading
Pour être capable de positionner une adresse sur une carte, pour calculer un itinéraire ou pour identifier l’ensemble des commerces dans un quartier donné, il est nécessaire de passer par une étape fondamentale : le géocodage. Cette opération consiste, à partir d’une adresse postale, comme “Av. Fonsny 20, 1060 Bruxelles”, d’une part à la “standardiser” (partie bordeaux de l’image ci-dessous), d’autre part à lui assigner des coordonnées géographiques (“location” dans l’image). Continue reading
Steeds meer gevoelige persoonsgegevens worden digitaal bewaard, terwijl cyberaanvallen steeds geavanceerder worden. Het verbeteren van de bescherming van persoonsgegevens geniet dan ook permanente aandacht. Continue reading