Isabelle Boydens(*), Isabelle Corbesier(**) et Gani Hamiti(**)
(*) Data Quality Expert, Research Team
(**) Data Quality Analyst, Databases Team
![]() De oorsprong van het concept ‘observability’
De oorsprong van het concept ‘observability’
De term observability in IT komt oorspronkelijk uit de software engineering.
Observability is een concept op hoog niveau dat betrekking heeft op het analyseren van de algemene toestand van een systeem van bijzonder heterogene en talrijke componenten, om kritisch gedrag te diagnosticeren en de oorzaken ervan te helpen identificeren (1). In de praktijk betekent dit het continu verzamelen en analyseren van basisinfrastructuurgegevens zoals processor- of opslagruimtegebruik in de loop van de tijd, evenals mogelijk complexere toepassings- of trackinglogs. Met de toename aan technologieën en componenten in moderne informatiesystemen kan genoeg observability bereiken soms veel ontwikkelingswerk vergen. Deze moeilijkheid heeft gezorgd voor een vruchtbare bodem voor de opkomst van tools voor observability, die kunnen worden gebruikt om gegevens te exploiteren die al door een systeem zijn geproduceerd, of om functionaliteiten voor gegevensproductie te enten op de componenten om het gedrag ervan beter zichtbaar te maken. (2)
Het soms geforceerde onderscheid tussen monitoring en observability kan in twijfel worden getrokken, in zoverre dat, net als observability, praktijken met het label ‘monitoring’ nooit worden ontwikkeld als een doel op zich, maar ook de toestand van het systeem willen diagnosticeren en incidenten voorkomen of corrigeren. Sommige referenties leggen overigens een verband tussen de twee concepten, omdat monitoring (meestal APM of Application Performance Monitoring ) en observability in dezelfde definitie zijn opgenomen, die dezelfde producten dekt. Ook al liggen de twee concepten niet op een lijn, ze zijn tenminste nauw verwant. Een goed niveau van observability vereist namelijk voldoende monitoring, goede documentatie en een grondige kennis van het systeem bij de teams die verantwoordelijk zijn voor het observeren ervan.
Van software naar data
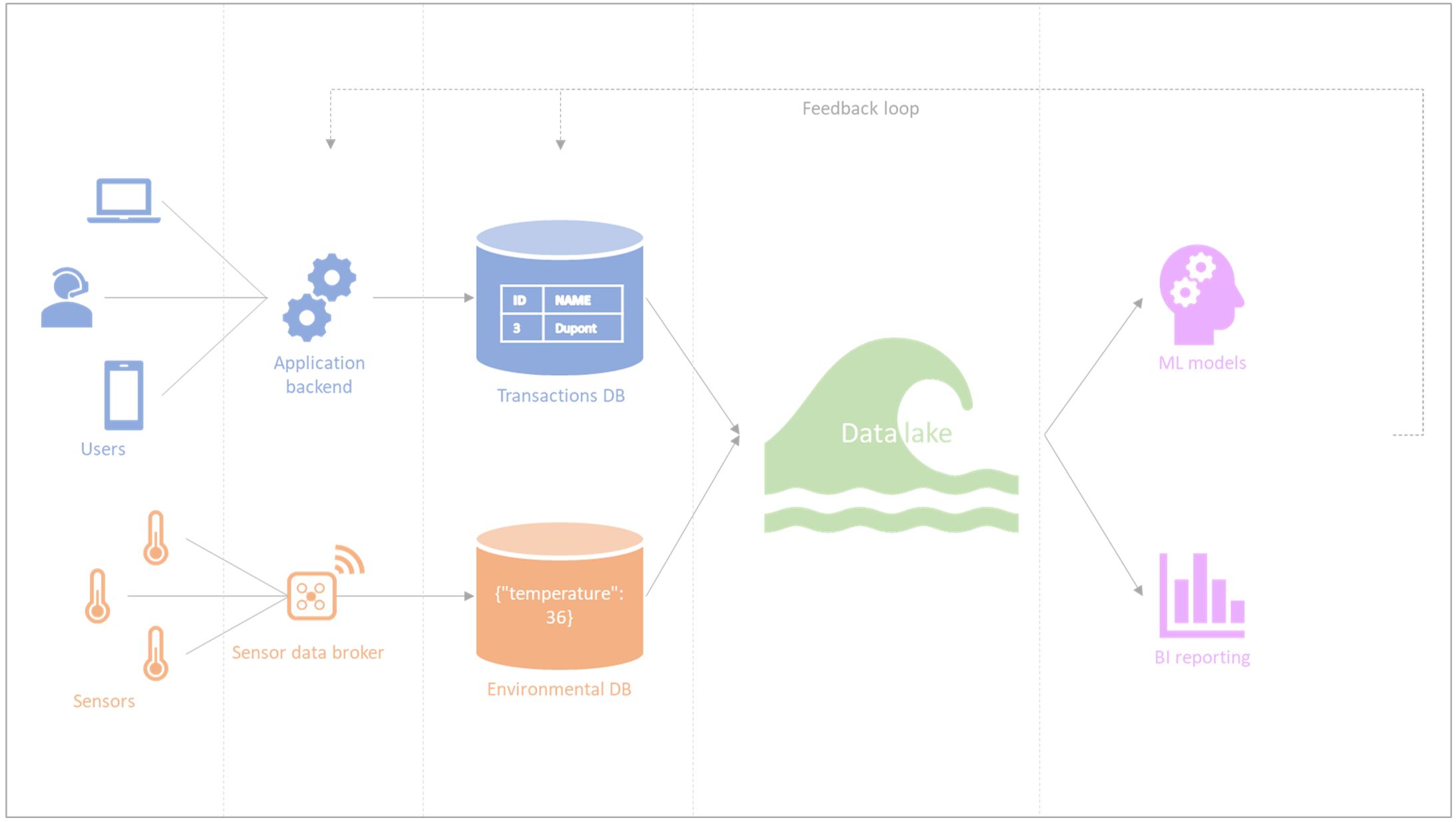
Figuur 1 – Informatiesysteem: heterogene componenten en feedbackloops
In navolging van data profiling (een kwaliteitsaudit van gegevens (3) die meestal voorafgaat aan de standaardiserings- en matchingfasen (4) in data quality tools) in de jaren 90, is data observability een recente omzetting (de term werd massaal populair rond 2022-2023) die is overgenomen door de infrastructuurwereld. Net zoals observability in deze context bestaat uit het kunnen diagnosticeren en verbeteren van de toestand van het systeem op basis van wat we ervan zien, is data observability het kunnen diagnosticeren van de algemene toestand van de gegevens van een systeem op basis van een gedetailleerd beeld dat is opgebouwd via de metadata. Data observability zal daarom gericht zijn op het samenbrengen van het monitoren, traceren en sorteren van gegevensgerelateerde incidenten, met als uiteindelijke doel het voorkomen of minimaliseren van de downtime die hieraan kan worden toegeschreven.
In een boek dat in 2022 gezamenlijk werd uitgegeven (5), identificeert Barr Moses, CEO van Monte Carlo Data, verschillende pijlers van data observability die al in de jaren 90 bestonden bij data profiling en sindsdien op grote schaal zijn hergebruikt. We onthouden de 4 volgende essentiële punten:
- De freshness: de bevestiging dat de gegevens up-to-date zijn en op gepaste wijze vernieuwd worden.
- De distribution: de bevestiging dat de gegevens zich in een aanvaardbaar interval bevinden, waarbij onverwachte waarden of nulwaarden vermeden worden.
- De completeness: de controle dat een dataset volledig is (aantal records of kolommen) zodat mogelijke problemen geïdentificeerd kunnen worden aan de bron. Merk op dat completeness fundamenteel onmogelijk met zekerheid te meten kan zijn; dit is bijvoorbeeld het geval bij de totale populatie van mensen die aan Alzheimer lijden of kanker hebben , waarbij ze in een vroeg stadium soms niet op de hoogte zijn.
- Lineage: de documentatie en het begrip van alle datasystemen van een organisatie, met inbegrip van upstream databronnen en downstream doelsystemen. In de praktijk zien we ook feedbackloops waarbij het gebruik van downstreamgegevens (bijvoorbeeld in ‘machine learning’- of BI-projecten) leidt tot veranderingen in het upstreamsysteem (zie Figuur 1). Op deze manier overschrijdt lineage de grenzen van technische benaderingen en vereist het aanzienlijke menselijke tussenkomst en een bijbehorend budget. Andere obstakels, die hieronder worden genoemd, kunnen zich voordoen bij het aan elkaar koppelen van informatiesystemen.
Verschillen tussen “data observability tools”, “data quality tools” (curatieve aanpak) en “ATMS-backtracking” (preventieve aanpak)
De documentatie over “data observability” tools verwijst naar “lineage” in technische zin. Dit houdt in dat je observeert hoe gegevens evolueren doorheen de verschillende componenten van een systeem; bijvoorbeeld van een front-end waar gegevens worden ingevoerd, via een REST API in back-end, een transactionele database, dan een datawarehouse, tot business intelligence of reportingsystemen. In tegenstelling tot ‘back tracking’, waarbij de gegevensstroom binnen het complexe informatiesysteem wordt bestudeerd, maar vooral stroomopwaarts en stroomafwaarts van het informatiesysteem (zie Figuur 2), hebben we het hier over ‘lineage’ tussen de componenten van het informatiesysteem waartoe de beheerders van de observability tool volledige toegang zouden moeten hebben om de mutatie van de gegevens in realtime te volgen.
Een reeks relatief recente tools dragen het label ‘data observability’ waarbinnen monitoring van data soms samengaat met systeemmonitoring ( (Bigeye, Collibra, Databand (IBM), DataBuck (FirstEigen), Kensu, Metaplane, Monte Carlo, Soda, …). Merk op dat bepaalde leveranciers van data quality tools zoals Informatica of Precisely naast profiling al ‘data observability’ opnemen. De term is vandaag blijkbaar erg in de mode. Het zal interessant zijn om de ontwikkeling van de tools in kwestie te volgen en, indien nodig, ze te testen.
Data quality tools (4) beperken zich daarentegen niet tot het observeren van gegevens, maar zijn bedoeld om er direct op in te grijpen. Dit is het doel van standaardisatiefunctionaliteiten (inclusief adressen) in batch of realtime (bijvoorbeeld via REST API), evenals mogelijk “fuzzy” ”data matching” door gebruik te maken van algoritmische families die specifiek zijn voor de te verwerken business cases.
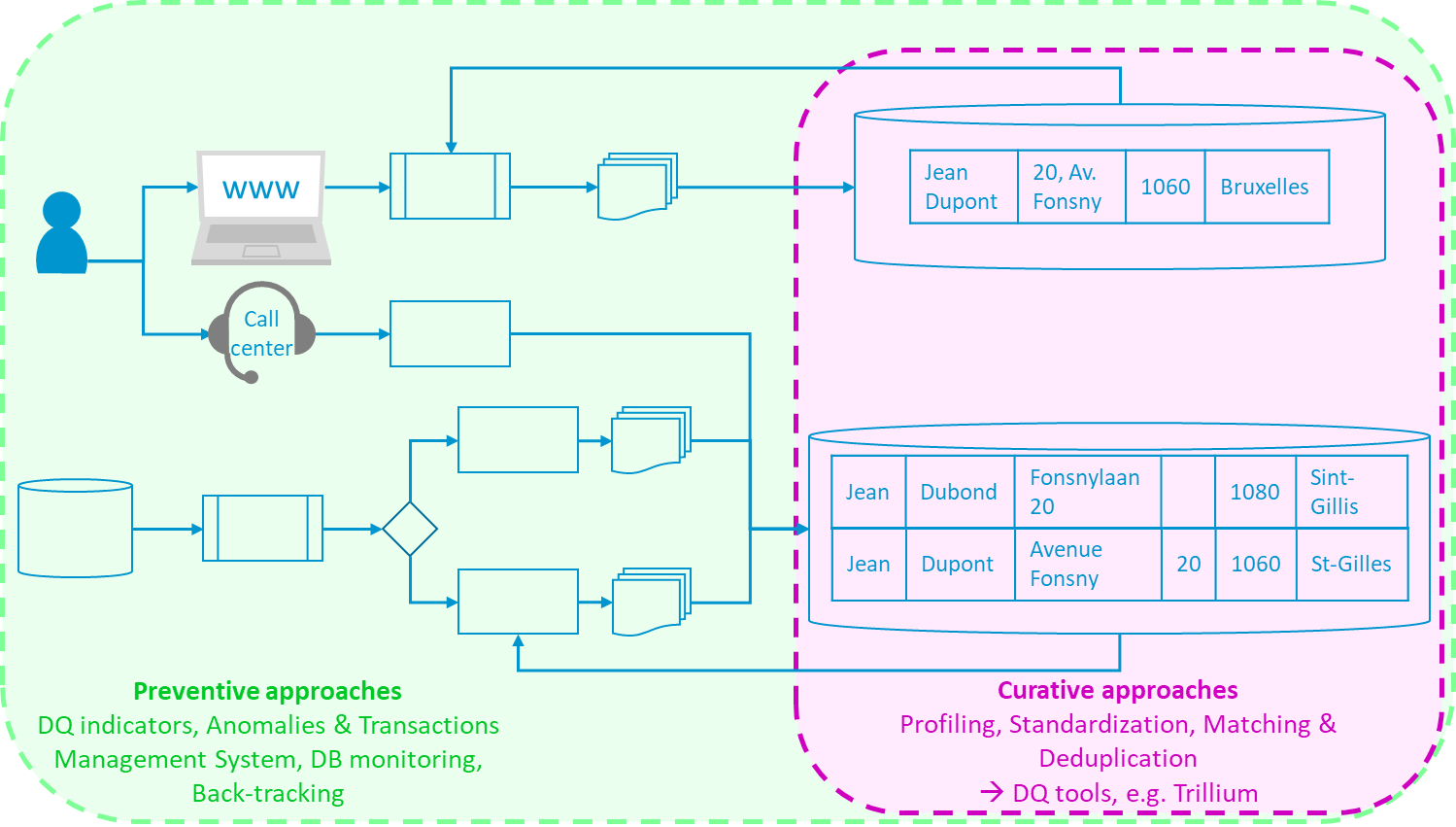
Figuur 2 – Preventieve en curatieve aanpakken
Kortom, tools voor data observability, die verwant zijn aan realtime ‘data profiling’, kunnen inspanningen ondersteunen om de gegevenskwaliteit te verbeteren, in het bijzonder door managers te helpen bij het identificeren en waarschuwen voor kwaliteitsproblemen. Het is echter nog steeds noodzakelijk om:
- specifieke hulpmiddelen voor data quality (4) te gebruiken in synergie met de business om strategieën te implementeren voor het oplossen van de gedetecteerde problemen (curatieve aanpakken);
- en/of een ATMS (6) te hebben waarmee backtracking kan worden uitgevoerd en problemen in een vroeg stadium kunnen worden voorkomen (preventieve aanpak).
Conclusie: recente op te volgen tools
In het algemeen kunnen we hieruit afleiden dat, opdat de observability die deze tools bieden een meetbare positieve impact heeft in een volwaardige bedrijfscontext:
- De organisatie die de tool gebruikt structureel gecentraliseerde toegang moet toestaan tot gegevensbronnen van verschillende aard en mate van kritiekheid. Dit punt brengt waarschijnlijk een groot aantal technische, juridische en organisatorische uitdagingen met zich mee:
- Scheiding van omgevingen: niet alle databronnen bevinden zich altijd in productieomgevingen.
- Netwerk- en stroomproblemen: alle benodigde componenten met elkaar laten communiceren is niet triviaal in de meeste organisaties van een bepaalde grootte en met een bepaald niveau van beveiligingseisen.
- Hoe zit het met toegangsrechten en GDPR? Niet zozeer vanuit het oogpunt van de technische haalbaarheid van de implementatie van GDPR-vereisten, maar vooral vanuit organisatorisch oogpunt.
- Scheiding van projecten en teams: de teams die verantwoordelijk zijn voor het toepassingsysteem vallen niet noodzakelijk onder dezelfde hiërarchie of dezelfde practices als de teams die de infrastructuur beheren of de teams die de gegevens stroomafwaarts exploiteren voor datamining of BI.
- Als het eerste punt behaald en opgelost is, moeten de systeembeheerders ook serieus samenwerken met de business over de indicatoren die gemonitord moeten worden, de kritische drempels, de waarschuwingen die geconfigureerd moeten worden en de definitie van de rollen: wie is verantwoordelijk voor welke gegevens en welke reacties worden verwacht in het geval van een probleem?
We zijn dus nog ver verwijderd van de bijna magische plug-and-play die door sommige online content wordt aangeprezen. Daarbij komt nog de realiteit van het onderzoeken van niet-triviale gegevensproblemen, die vaak verder gaat dan de grenzen van een technisch informatiesysteem, hoe complex ook. Om deze redenen is data quality meer dan ooit afhankelijk van menselijke tussenkomst en interpretatie wanneer de inzet dit rechtvaardigt.
Referenties
- (1) https://about.gitlab.com/blog/2022/06/14/observability-vs-monitoring-in-devops/
- (2) https://www.ibm.com/topics/observability
- (3) Olson Data Quality: The Accuracy Dimension (The Morgan Kaufmann Series in Data Management Systems), 2003.
- (4) BOYDENS I., CORBESIER I. et HAMITI G., Data Quality Tools : retours d’expérience et nouveautés, 07/12/2021.
- (5) https://www.oreilly.com/library/view/data-quality-fundamentals/9781098112035/
- (6) BOYDENS I., HAMITI G. et VAN EECKHOUT R., Un service au cœur de la qualité des données. Présentation d’un prototype d’ATMS. In Le Courrier des statistiques, Paris, INSEE, juni 2021, nr. 6, p. 100-122. PDF-bestand / Link naar het Blad en naar het artikel.
Deze post is een gezamenlijke bijdrage van Isabelle Boydens, Data Quality Expert bij Smals Research, Isabelle Corbesier en Gani Hamiti, Data Quality Analisten bij Smals, Databases Team. Dit artikel is geschreven onder hun eigen naam en weerspiegelt op geen enkele wijze de standpunten van Smals.
Leave a Reply