Data quality management, regelmatig besproken in deze blog, bestaat vaak uit het verwerken (vergelijken, vergemakkelijken, transformeren, “fonetiseren”, enz.) van karakterketens: namen van mensen, ondernemingen, steden, straten, telefoonnummers, e-mailadressen, …
In deze blogpost nemen we een kijkje naar het soort problemen dat kan worden opgespoord wanneer data gekoppeld raken met geografische coördinaten (breedtegraden, lengtegraden), rekening houdend met open data van het project BeSt Address (Belgian Street Address), van de FOD BOSA, authentieke bron voor adressen in België. Dit project verzamelt en consolideert gegevens van de gewesten (UrbiS voor het Brussels Gewest, het Adressenregister voor Vlaanderen en ICAR voor Wallonië), die op hun beurt adresgegevens ophalen die verzameld zijn door elke gemeente, de instantie die verantwoordelijk is voor de toewijzing van adressen. Een reeks CSV- of XML-bestanden kan hier worden gedownload met de officiële spelling en geografische coördinaten van elk adres in België.
Onze ervaring heeft ons geleerd dat de BeSt Address data veruit de meest kwalitatieve zijn in vergelijking met andere officiële bronnen die adressen bevatten (Rijksregister, Werkgeversregister, Kruispuntbank van Ondernemingen, enz.), ten minste de klassieke aspecten van datakwaliteit (consistentie van namen, afwezigheid van afkortingen, enz.), het resultaat van de enorme inspanningen van de teams in de gewesten en de FOD BOSA. Toch konden we een aantal anomalieën vinden die alleen geïdentificeerd konden worden door naar de geografische gegevens en ruimtelijke analyses te kijken.
De meeste geïdentificeerde anomalieën komen overeen met verkeerd geplaatste adressen (verkeerde coördinaten) of problematische postcodes. Opschoning kan alleen worden uitgevoerd door de entiteiten op het terrein, d.w.z. de gemeenten.
Merk op dat de anomalieën die hieronder worden gepresenteerd het resultaat zijn van een “academische” analyse. Deze is al besproken met een aantal mensen van de relevante instanties (gewesten, rijksregister, FOD BOSA, NGI, etc.), en sommige van deze afwijkingen worden aanvaardbaar geacht. Deze blogpost wil geen kritiek uiten op de kwaliteit van de data, maar simpelweg een methodologie presenteren en deze illustreren met een relevante databron.
Context
Zoals in een vorige blogpost is beschreven, bestaat België op het moment van schrijven uit 581 gemeenten (dit aantal zal de komende maanden afnemen na een reeks fusies van gemeenten). Elk van deze gemeenten bestaat uit een of meer postcodes (verbonden met een naam in Brussel en Vlaanderen), en elk van deze postcodes kan een of meer deelgemeenten of lokaliteiten bevatten (part of municipality in Wallonië, in BeSt Address-jargon).
Voor de onderstaande analyse baseerden we ons op de CSV-bestanden die beschikbaar zijn op https://opendata.bosa.be/, en voerden we vier soorten analyses uit:
- In de eerste analyse kijken we of alle busnummers op hetzelfde adres dicht bij elkaar liggen;
- In de tweede vergelijken we de grenzen van de postcodes gedefinieerd door bpost (de Belgische postdienst) met de postcodes van adressn uit BeSt Adress;
- In de derde analyse gaan we op zoek naar inconsistenties in straatnamen die geografisch dicht bij elkaar liggen (bv. een ‘rue Roi Albert I‘ naast een ’rue du Roi Albert I’);
- In de vierde zoeken we naar geometrische afwijkingen in de vorm van een straat.
Inconsistentie van bussen
Zoals eerder beschreven bevat een adres altijd een ‘huisnummer’, dat verwijst naar het gebouw, en soms een ‘ busnummer’, dat verwijst naar de wooneenheid binnen dat gebouw. In BeSt Address vinden we voor elk adres met een bus altijd een gelijkwaardig basisadres (zelfde straat, postcode, nummer) zonder bus. Laten we bijvoorbeeld zeggen dat de Fonsnylaan 20 twee bussen heeft, ‘bus 1’ en ‘bus 2’: we vinden drie items in BeSt Address: ‘Fonsnylaan 20’; ‘Fonsnylaan 20 bus 1’ en ‘Fonsnylaan 20 bus 2’.
Voor elk adres (straat, postcode, nummer) hebben we gecontroleerd of de coördinaten die bij de bussen horen niet abnormaal ver uit elkaar liggen. In de overgrote meerderheid van de gevallen hebben de verschillende bussen met hetzelfde nummer allemaal dezelfde coördinaten, maar dit is niet altijd het geval.
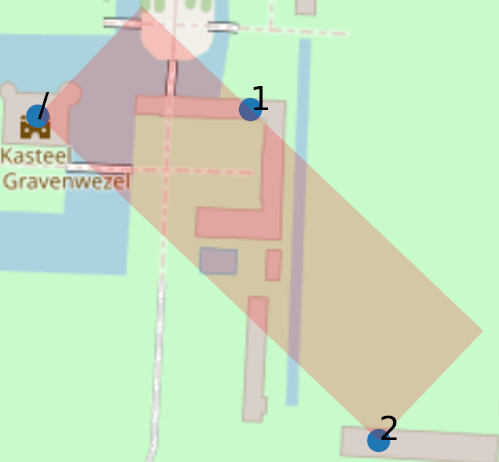
Voor elk adres met busnummers schetsen we de ‘minimum rotated rectangle’ , d.w.z. de rechthoek met de minimale oppervlakte die alle punten omvat (de coördinaten van het ‘basis’-adres, voorgesteld door ‘/’, en die van elk van de bussen), waarbij elke rotatie van de rechthoek mogelijk is. Zo’n rechthoek die twee punten omvat zal een breedte van nul hebben en een lengte gelijk aan de afstand tussen de punten. In het geval van meerdere niet-uitgelijnde punten zullen beide afmetingen positief zijn.
De anomalieën werden voornamelijk gedetecteerd in Vlaanderen, met meer dan 100 gevallen. In Wallonië zijn de coördinaten van de verschillende bussen steeds gelijk aan de coördinaten van het basisadres. In Brussel werden slechts twee afwijkingen vastgesteld.
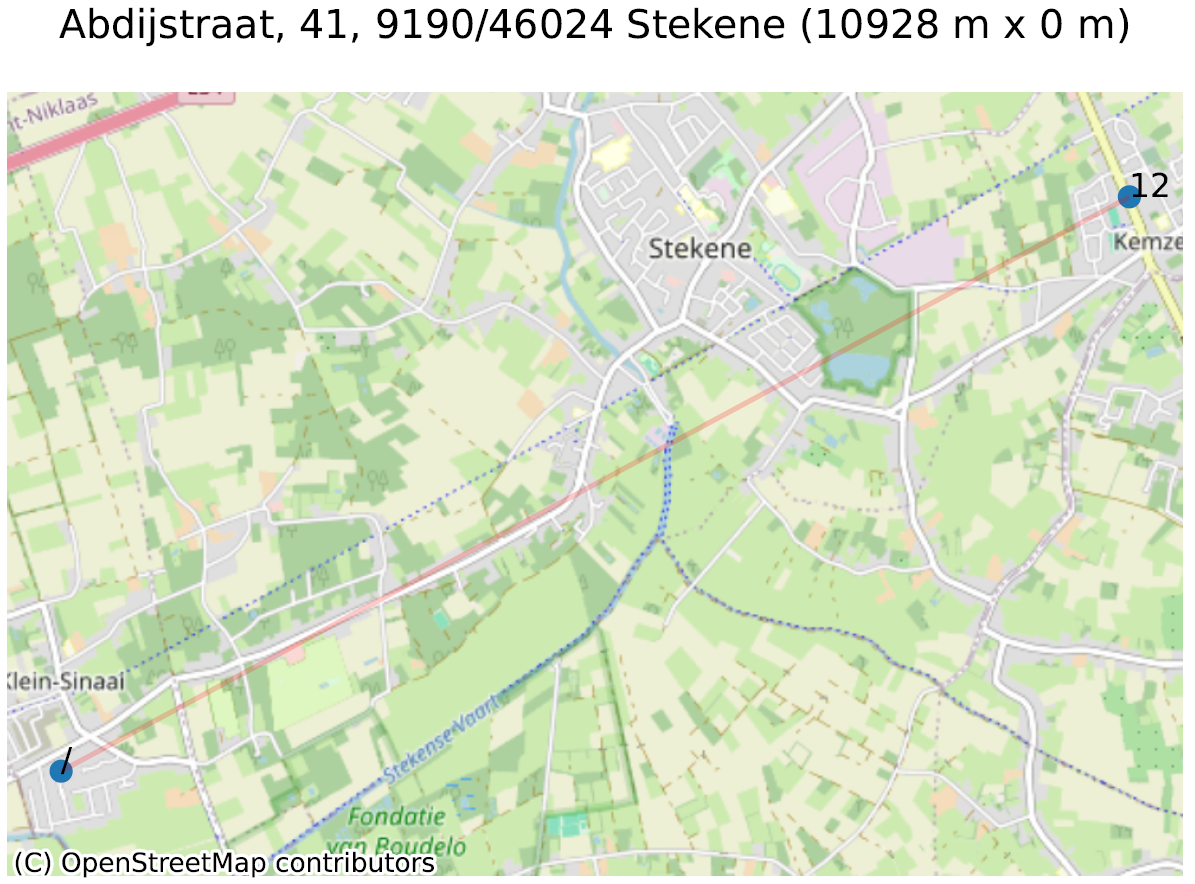
Om dit te illustreren nemen we twee voorbeelden, weergegeven in de figuur hieronder. Het eerste voorbeeld (Abdijstraat, 41 te 9140 Stekene) toont aan dat het basisadres (Abdijstraat, 41, voorgesteld door een ‘/’) zich op 11 kilometer van Abdijstraat, 41 bus 12 bevindt. We vonden bijna honderd zeer vergelijkbare voorbeelden.
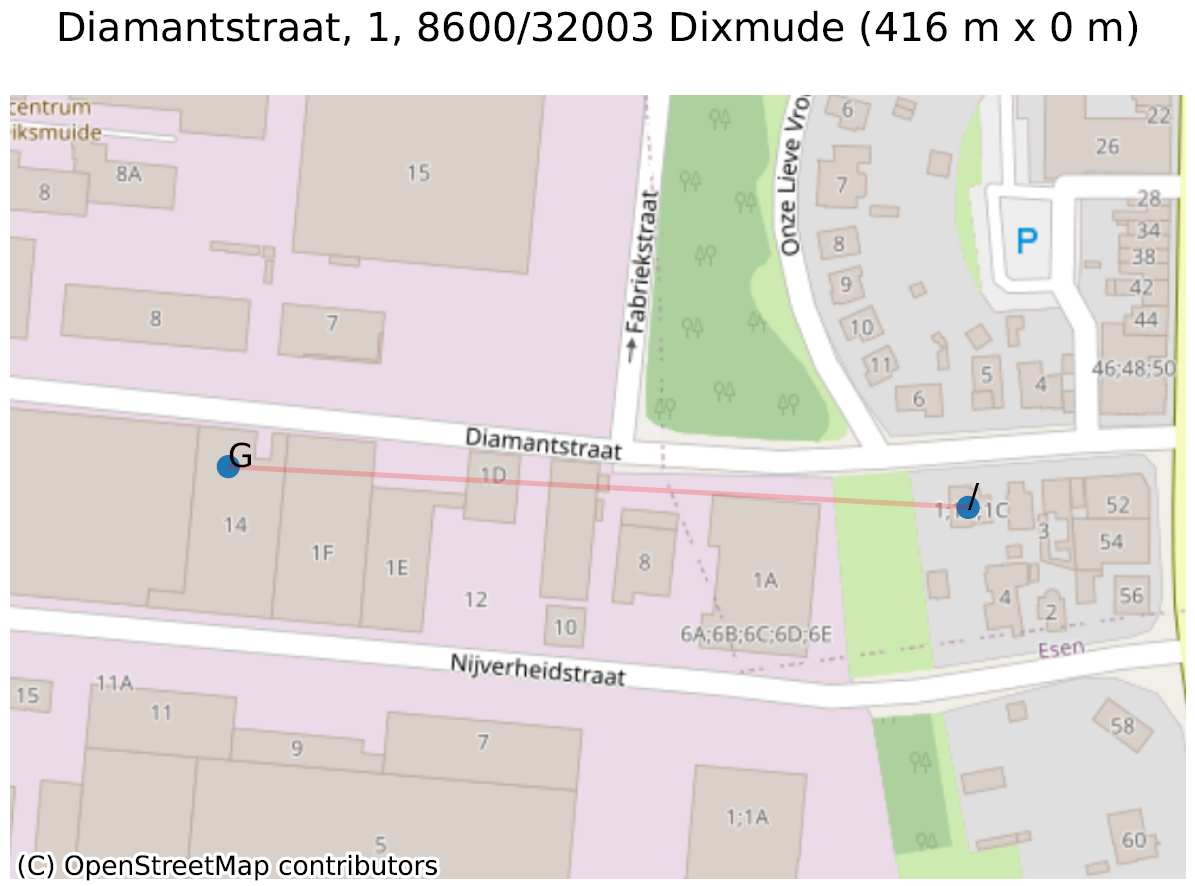
Het tweede is een gevolg van het probleem dat in ons vorige artikel werd geïllustreerd: om adressen tussen ‘1’ en ‘3’ te maken, kun je ze maken met huisnummers ‘1A’, ‘1B’, ‘1C’… (zonder busnummer), of ze allemaal ‘nummer 1’ noemen, maar met een busnummer ‘A’, ‘B’, ‘C’… In de ‘Diamantstraat’ in Diksmuide is (ongetwijfeld per ongeluk) een hybride keuze gemaakt: naast de 1 vinden we ‘1A’, ‘1B’, … ‘1F’, dan … ‘1 bus G’! Dit creëert een grote afstand tussen de 1 (basisadres) en de 1 (bus G).
Postgrenzen
In deze analyse vergelijken we de door bpost gedefinieerde postcodegrenzen. Om dit te doen, kijken we voor elk BeSt-adres in welke bpost-polygoon het valt en selecteren we de adressen waarvoor er een inconsistentie is tussen de BeSt-postcode en de bpost-postcode.
Om nauwkeurigheidsproblemen van een punt dat precies op de grens ligt te voorkomen, verwijderen we een strook van 50 meter uit de contouren in de postcodes die door bpost zijn gedefinieerd. Een inconsistentie wordt daarom slechts geïdentificeerd wanneer een adres in een P1 postcode (volgens BeSt) eigenlijk in de polygoon van een P2 postcode (volgens bpost) ligt, met P1 ≠ P2.
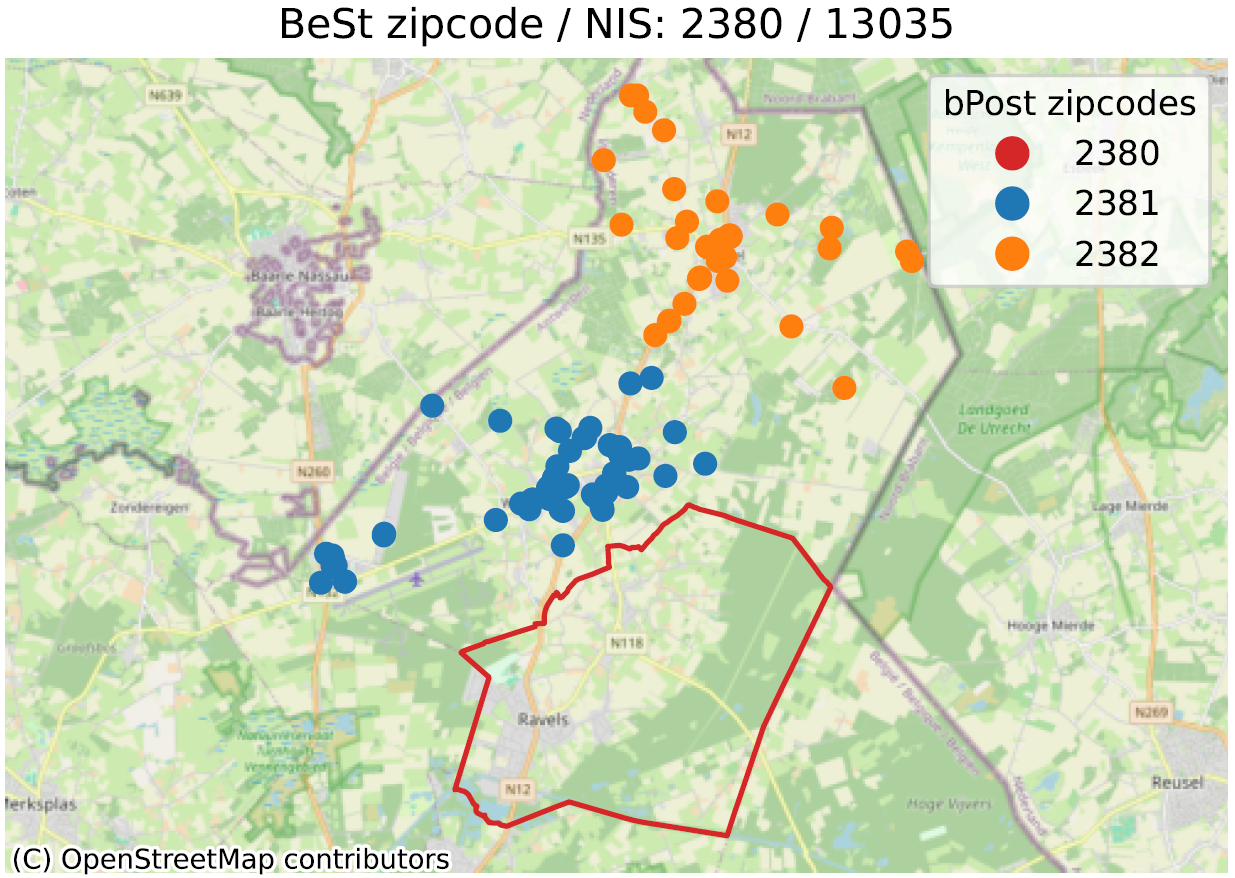
In de onderstaande afbeeldingen kunnen we enkele van de geïdentificeerde voorbeelden zien. De rode lijn stelt de grens voor die overeenkomt met de postcode in kwestie, volgens bpost (6700 voor het hoofdvoorbeeld). Binnen deze lijn bevinden zich een groot aantal BeSt-adressen die bij dezelfde postcode horen. Deze adressen worden hier niet getoond om het beeld niet te overladen. De gekleurde stippen buiten de rode omlijning zijn dus adressen die BeSt associeert met de code in de titel, maar die volgens het postkantoor de postcode hebben uit de legende (6704 in het blauw, 6706 in het oranje voor de 1e voorbeeld).
Merk op dat de geregistreerde ‘uitwisselingen’ altijd binnen dezelfde gemeente liggen (Aarlen voor het voorbeeld). Terwijl BeSt ervan uitgaat dat alle adressen in de gemeente Aarlen op 6700 liggen, gaat bpost er wel van uit dat een deel van het grondgebied op 6704 (Guirsch) of 6706 (Autelbas-Barnich) ligt, twee postcodes die BeSt niet kent.
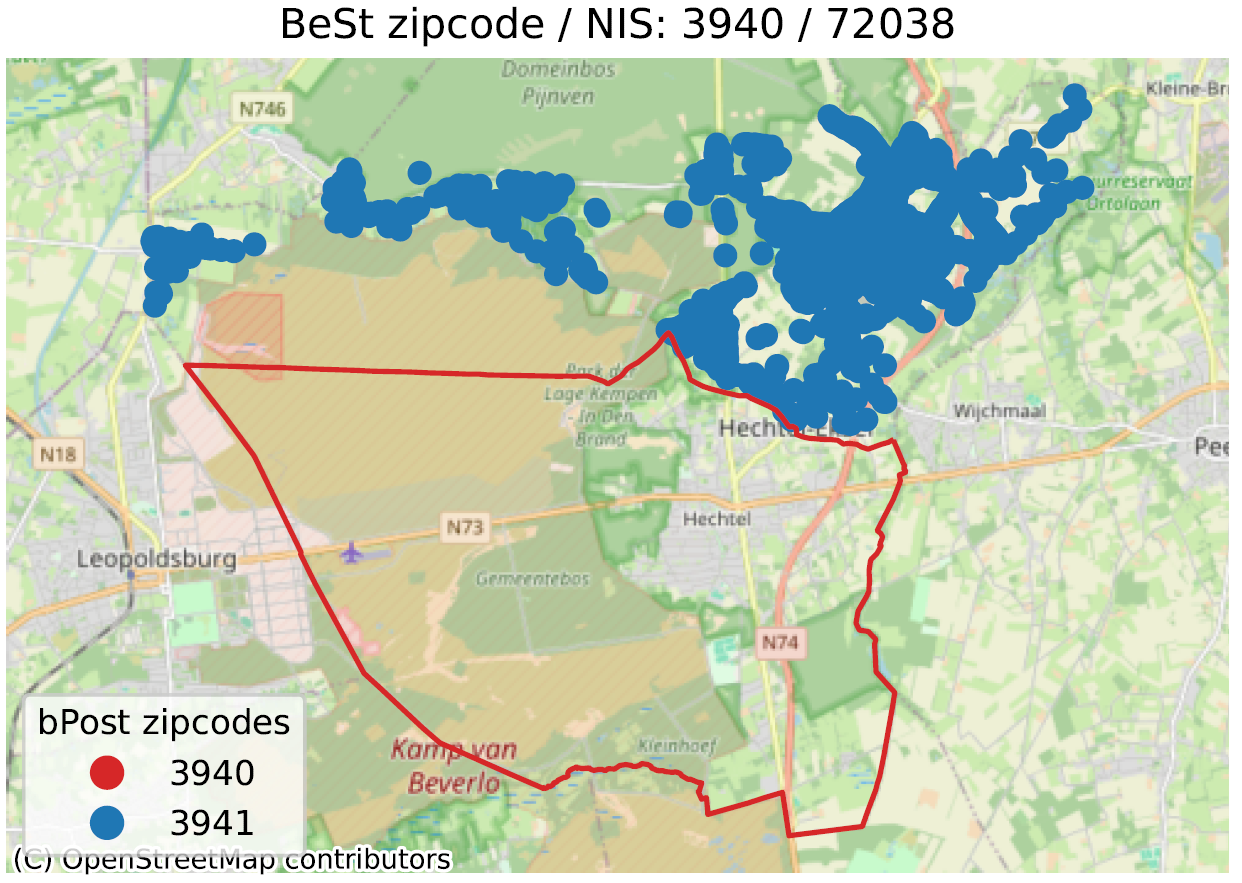

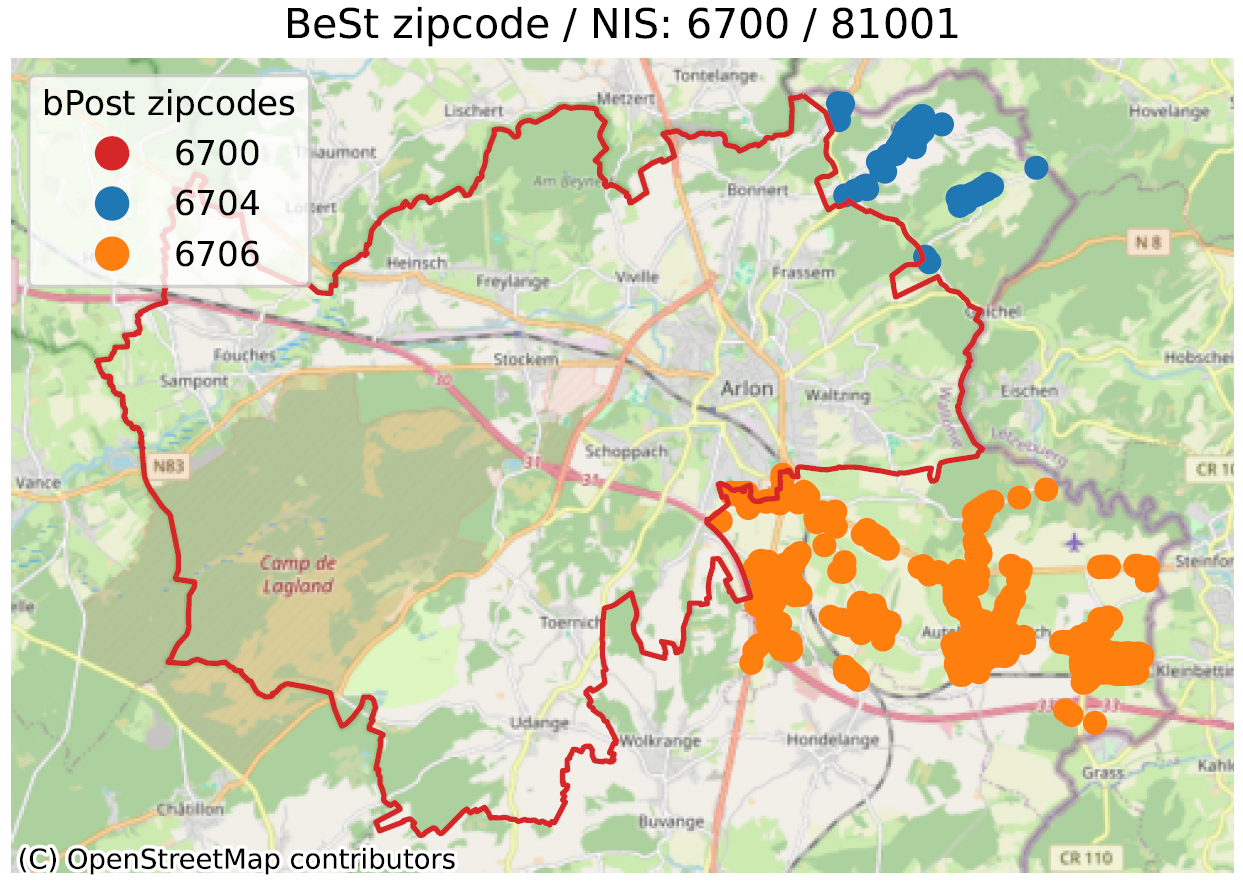
Dit is niet alleen een kwestie van een bestand (Shapefile) dat niet up-to-date is op de website van de Post: de online adresvalidatietool van bpost is consistent met de getoonde postcodes.
Tijdens sommige gesprekken kregen we te horen dat gemeenten de vrijheid hebben om de toewijzing van postcodes op hun grondgebied te wijzigen. Hierover bestaat echter geen consensus: in de “Gids voor het vaststellen en toekennen van adressen”, staat dat “Postcodes en hun systematisering zijn echter eigendom van de dienstverlener van de universele postdienst, in voorkomend geval (…) bpost. Ze kunnen alleen worden toegekend en gewijzigd op basis van een voorstel van bpost en na een gemotiveerd advies van het BIPT en de goedkeuring van de minister overeenkomstig artikel 135 van de wet van 21 maart 1991. (Artikel 22)”.
We troffen iets meer dan 8000 anomalieën aan in Wallonië (op een totaal van 1,85 miljoen relevante adressen), ~ 11 000 in Vlaanderen (op 3,83 miljoen) en een marginaal aantal in Brussel (op 860 000). Merk op dat sommige afwijkingen aanvaardbaar zijn, zoals gebouwen (kastelen, boerderijen, enz.) die ver van de voordeur liggen. BeSt lokaliseert het gebouw, maar de postcode komt overeen met die van de ingang.
Inconsistentie van namen
Voor deze analyse gaan we een ‘klassieke’ benadering op basis van karakterketen combineren met een geografische benadering. We starten met het identificeren van de lijst van alle paren van aangrenzende straten (d.w.z. de ene heeft een adres op minder dan 100 meter van de andere). Vervolgens controleren we op kleine verschillen in straatnamen. We zien meestal twee situaties:
- Straten die verschillende gemeenten doorkruisen en in elke gemeente een andere schrijfwijze hebben: ‘Rue de Monténégro, 1060’, vs ‘Rue du Monténégro, 1190’;
- Straten met twee verschillende schrijfwijzen binnen dezelfde gemeente: ‘Chaussée Brunehault’ of ‘Chaussée Brunehaut’, in 4452 in beide gevallen.
Er zijn ook een paar fout-positieven: ‘Rue de Mars’ vs ‘Rue de Mai’. We schrappen namen uit onze vergelijkingen die identiek zijn op een geïsoleerde laatste letter na (“Hensellaan A” vs “Hensellaan B”), evenals namen waarbij slechts een cijfer verandert (‘5de Zijweg’ vs ‘6de Zijweg’).
Met betrekking tot de eerste situatie, waarbij de naam verandert wanneer men van de ene gemeente naar de andere gaat, is het betreurenswaardig dat er een gebrek aan consistentie is, wat in strijd is met artikel 5 van de hierboven beschreven richtlijn, waarin staat dat “[a]ls een weg zich uitstrekt over het grondgebied van meerdere gemeenten en die weg dezelfde naam behoudt, dan moeten die gemeenten erop toezien dat de spelling van die straatnaam in alle betrokken gemeenten dezelfde is”. De richtlijn is echter niet bindend, gemeenten kunnen dus een eigen spelling behouden.

Het is echter de moeite waard om je af te vragen of de spelling die in BeSt wordt gebruikt (zoals doorgegeven door de gemeenten) echt de juiste is. Bijvoorbeeld, ‘Rue Walckiers’ in 1030 Schaarbeek is een uitbreiding van ‘Rue Walkiers’ in 1140 Evere. Het (enige) Schaarbeekse bord voor deze straat schrijft het echter als … ‘Rue Walkiers’! Hetzelfde geldt voor het (kleine) deel van de Tervuerenlaan in Oudergem, dat als dusdanig gespeld wordt in Sint-Pieters-Woluwe en op de straatnaambordjes in Oudergem, maar in Oudergem vermeld staat als ‘Tervurenlaan’. Er zijn nog veel meer voorbeelden.
De situatie waarin, binnen dezelfde gemeente, soms zelfs voor dezelfde postcode, twee straatsecties niet op dezelfde manier worden gespeld, is een duidelijke indicatie van een probleem met de kwaliteit van de gegevens. We hebben tientallen van dergelijke gevallen geïdentificeerd, voornamelijk in Wallonië, en noemen er hier slechts enkele ter illustratie.
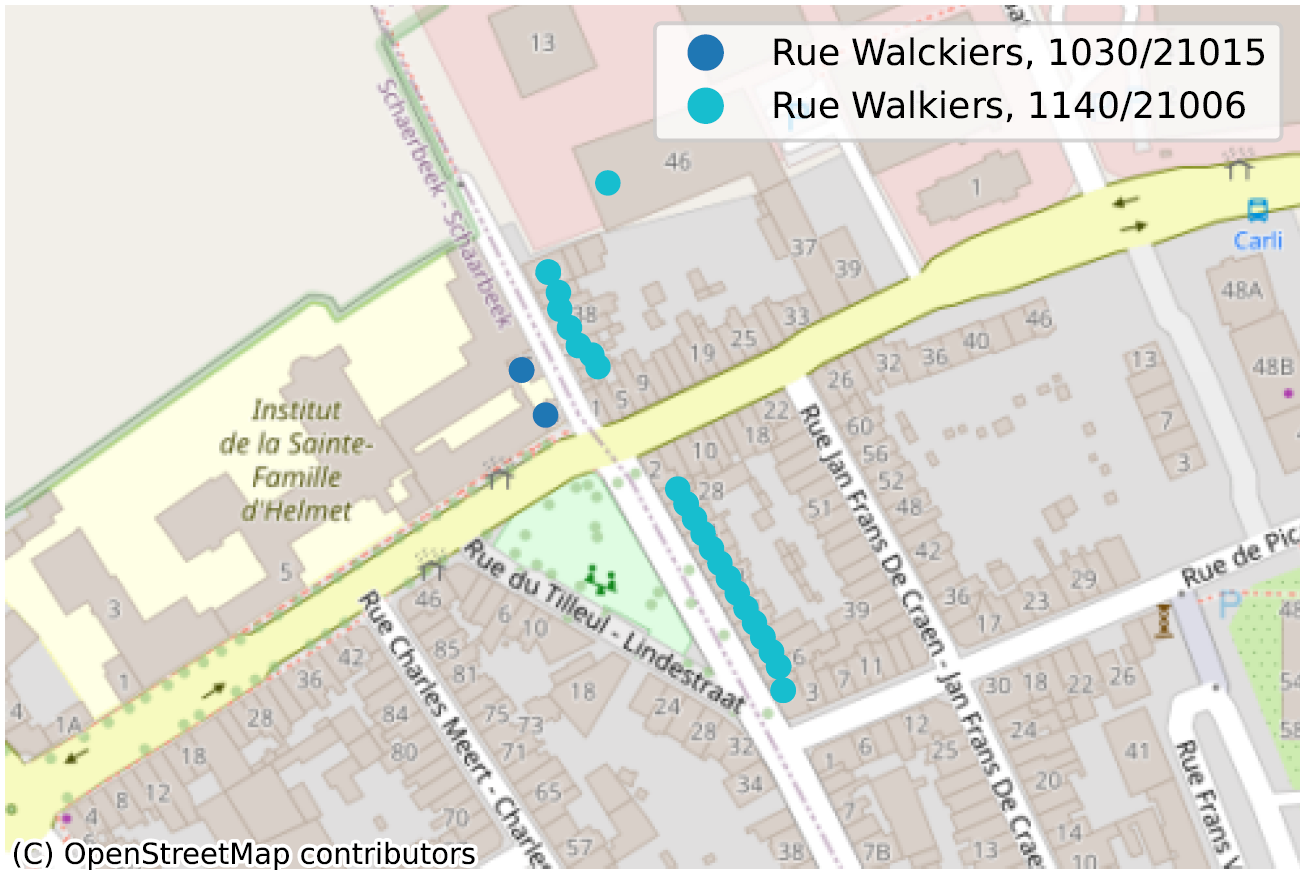
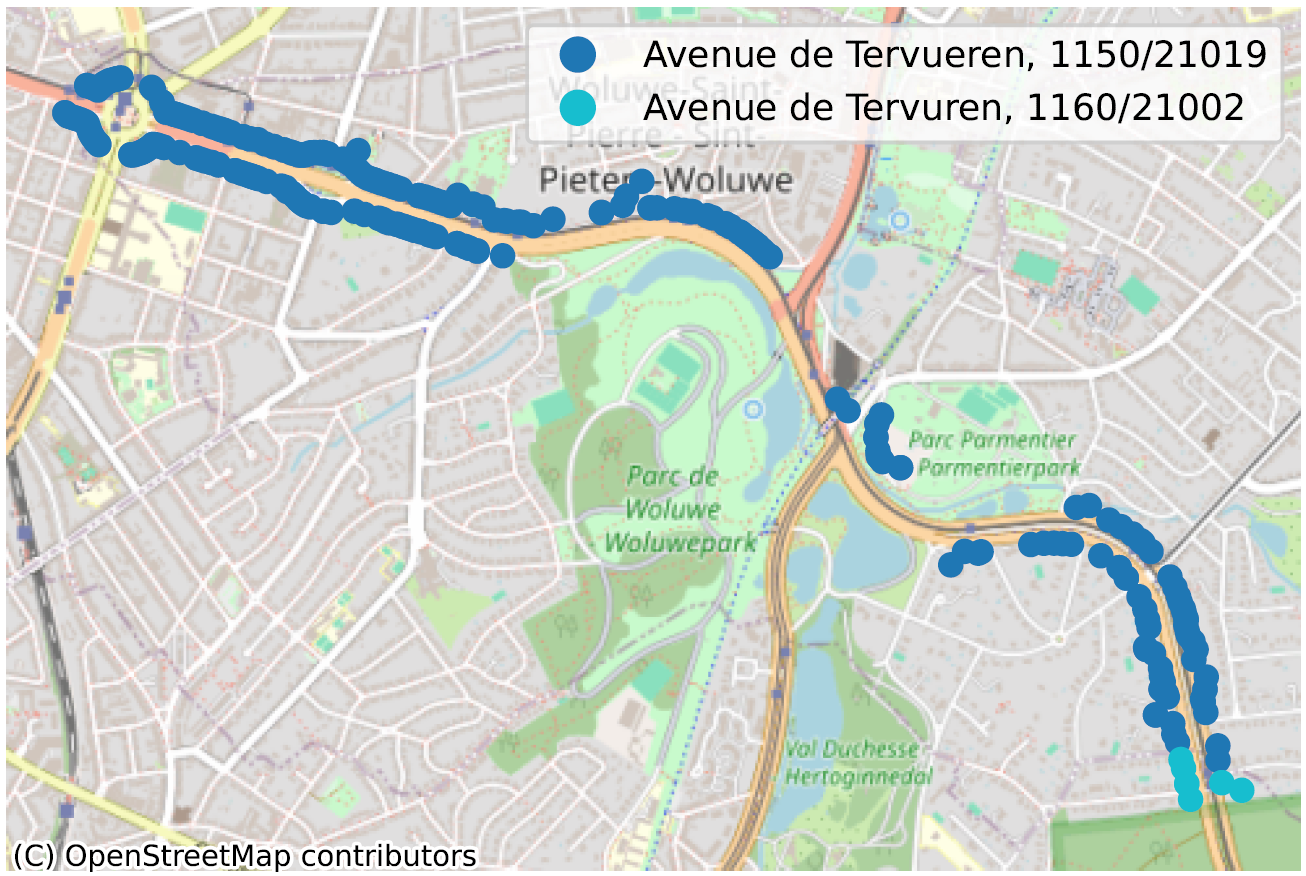
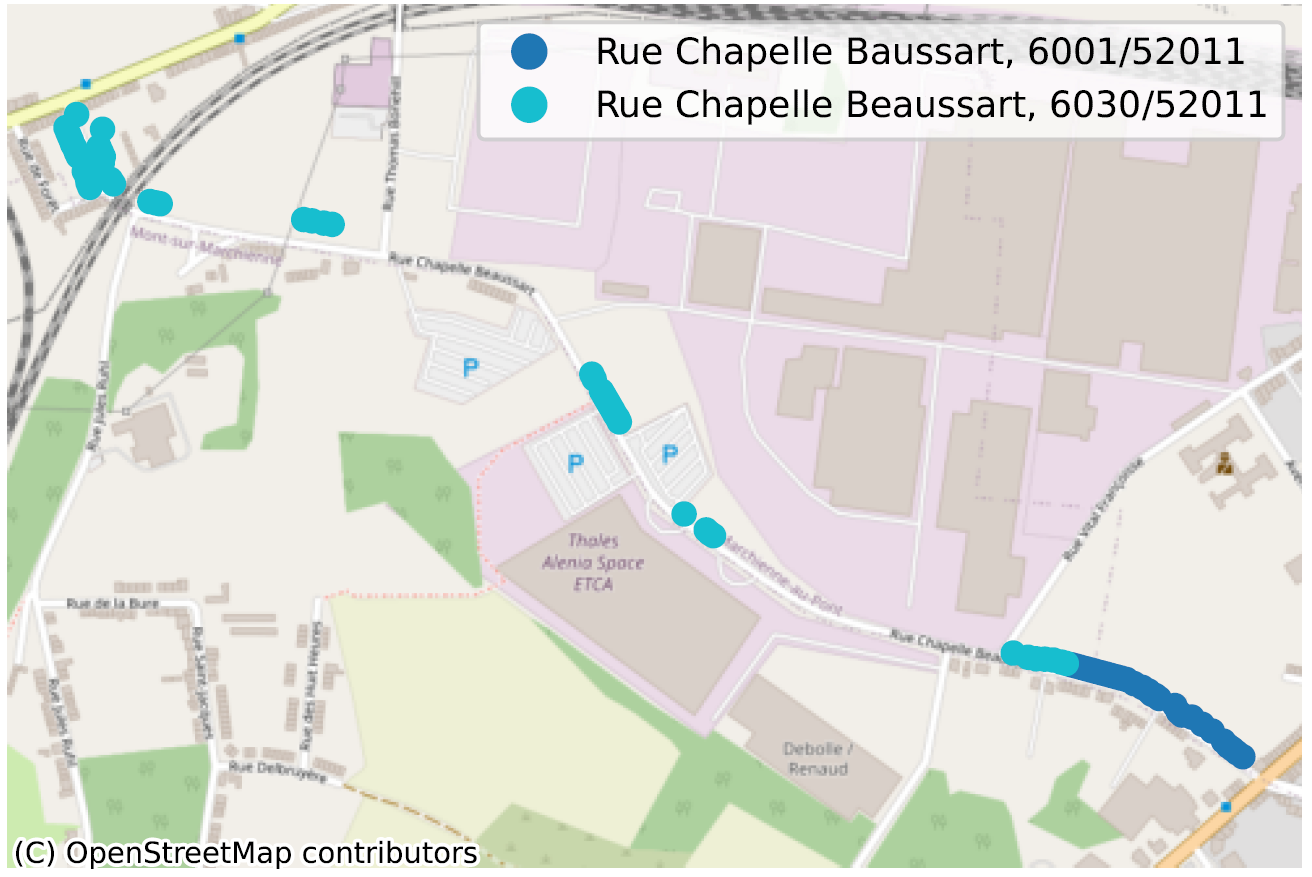
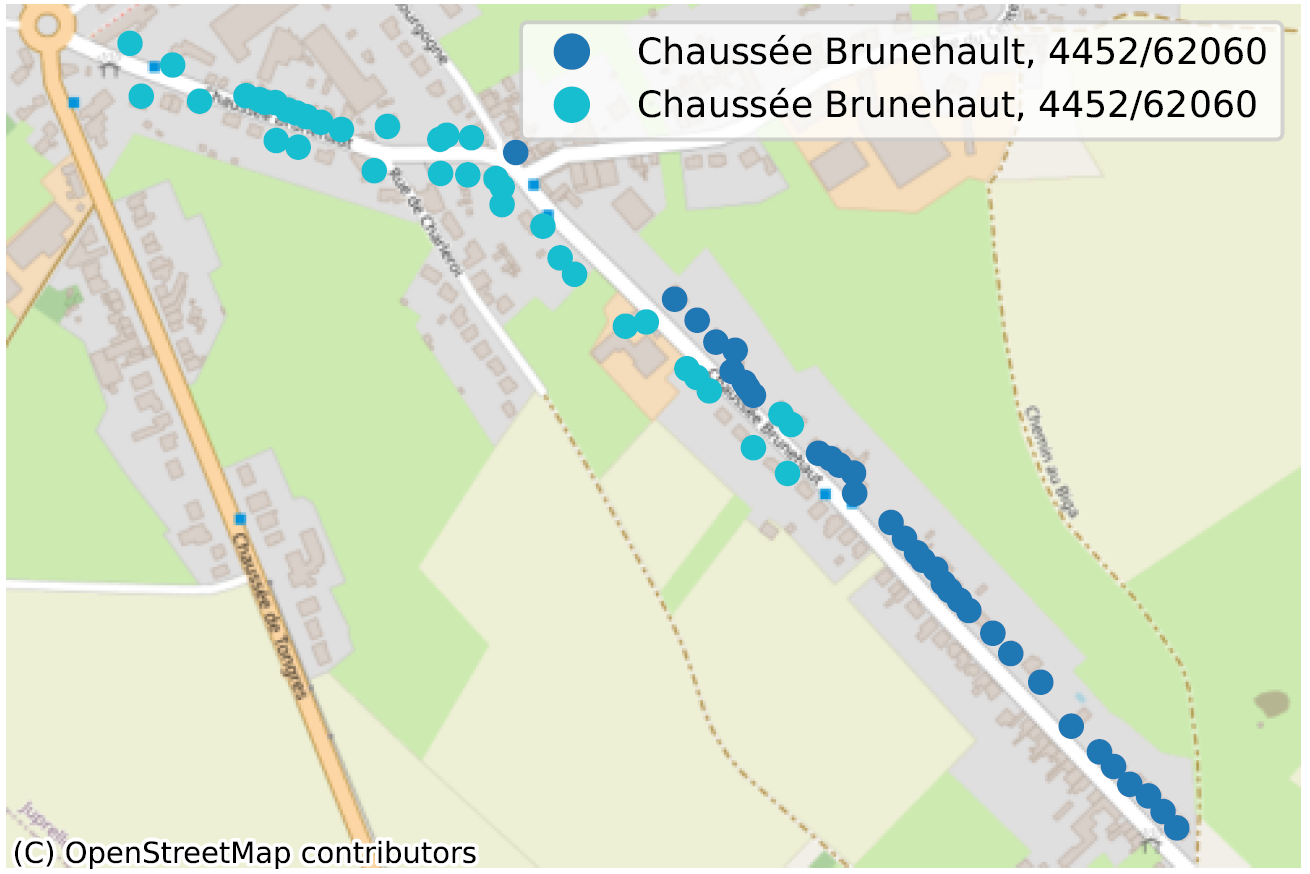
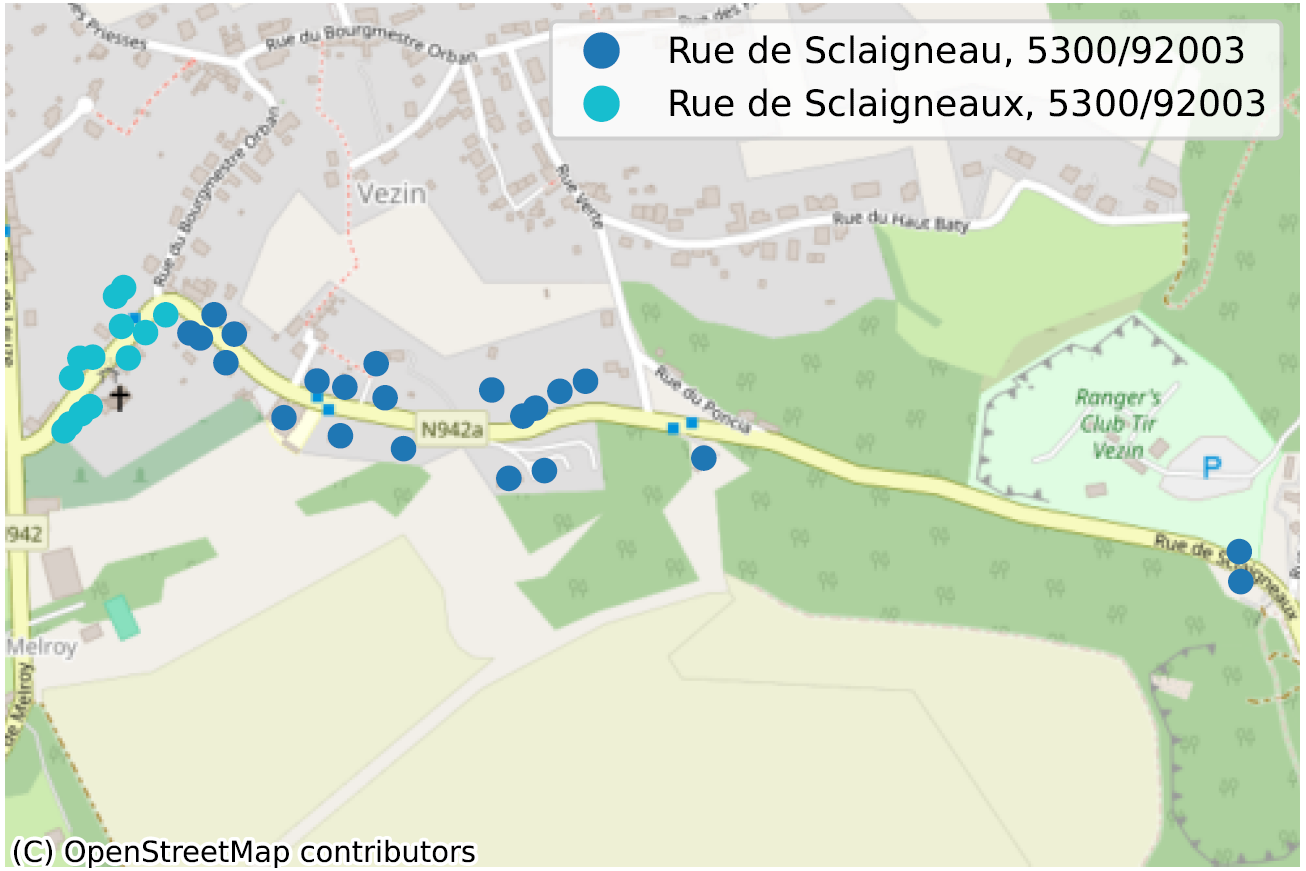
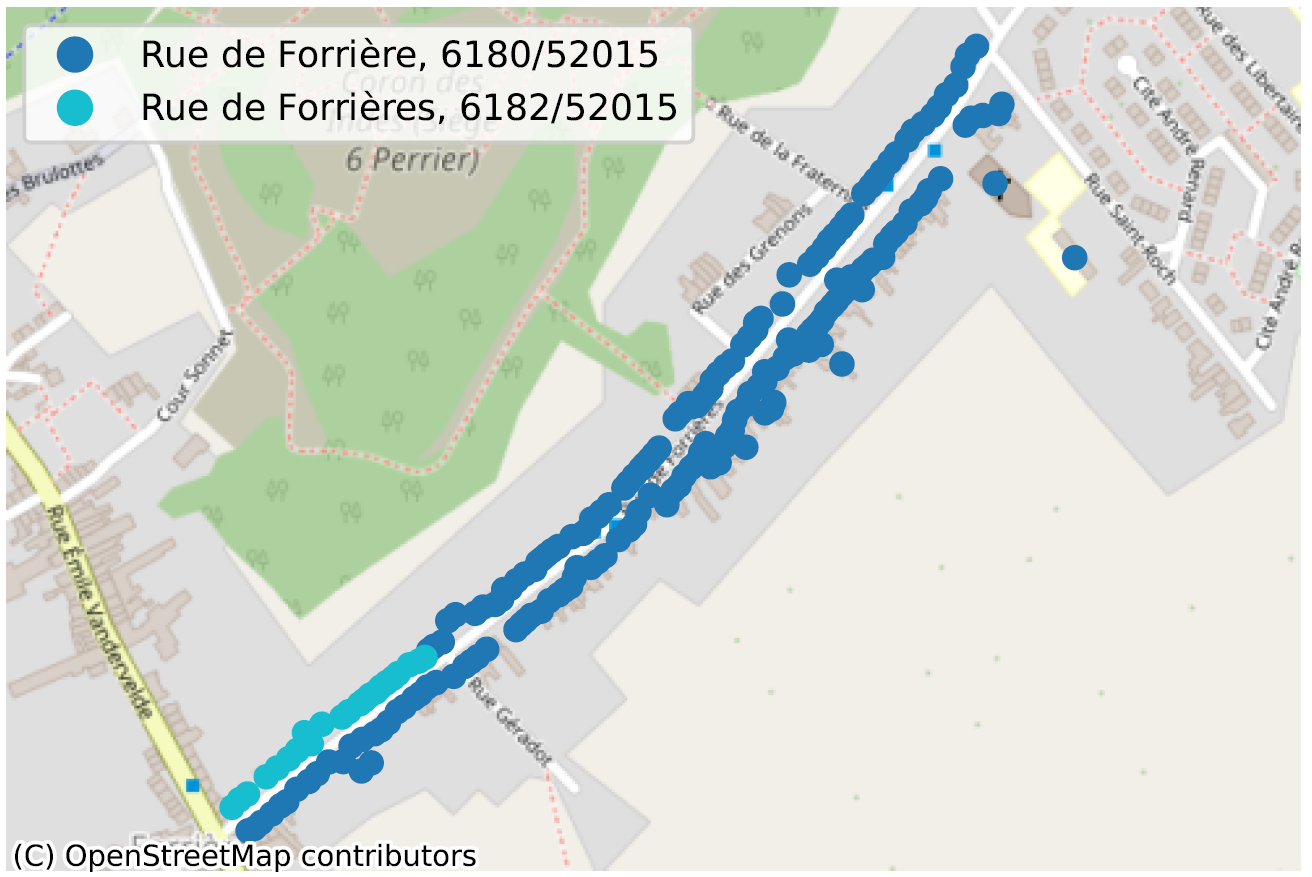
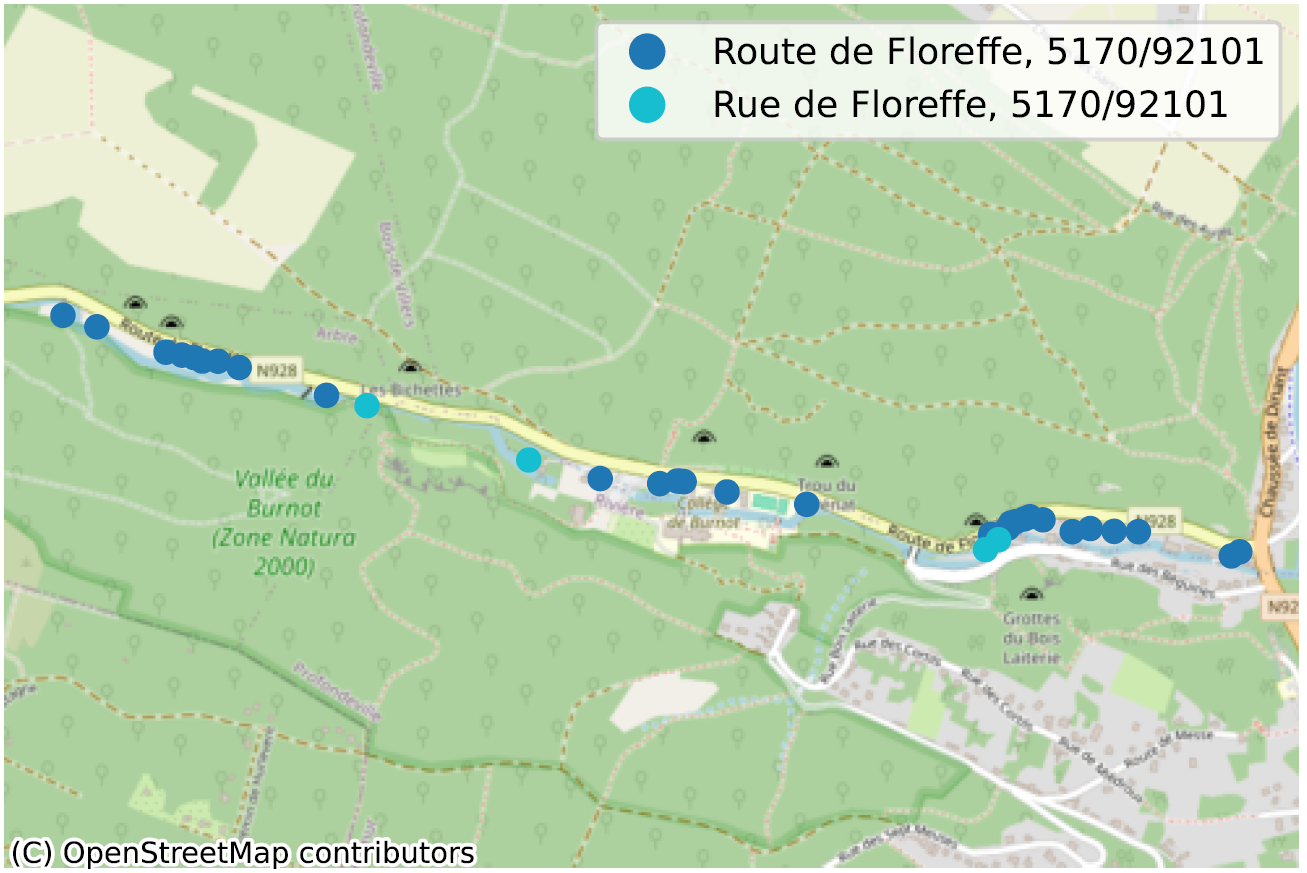
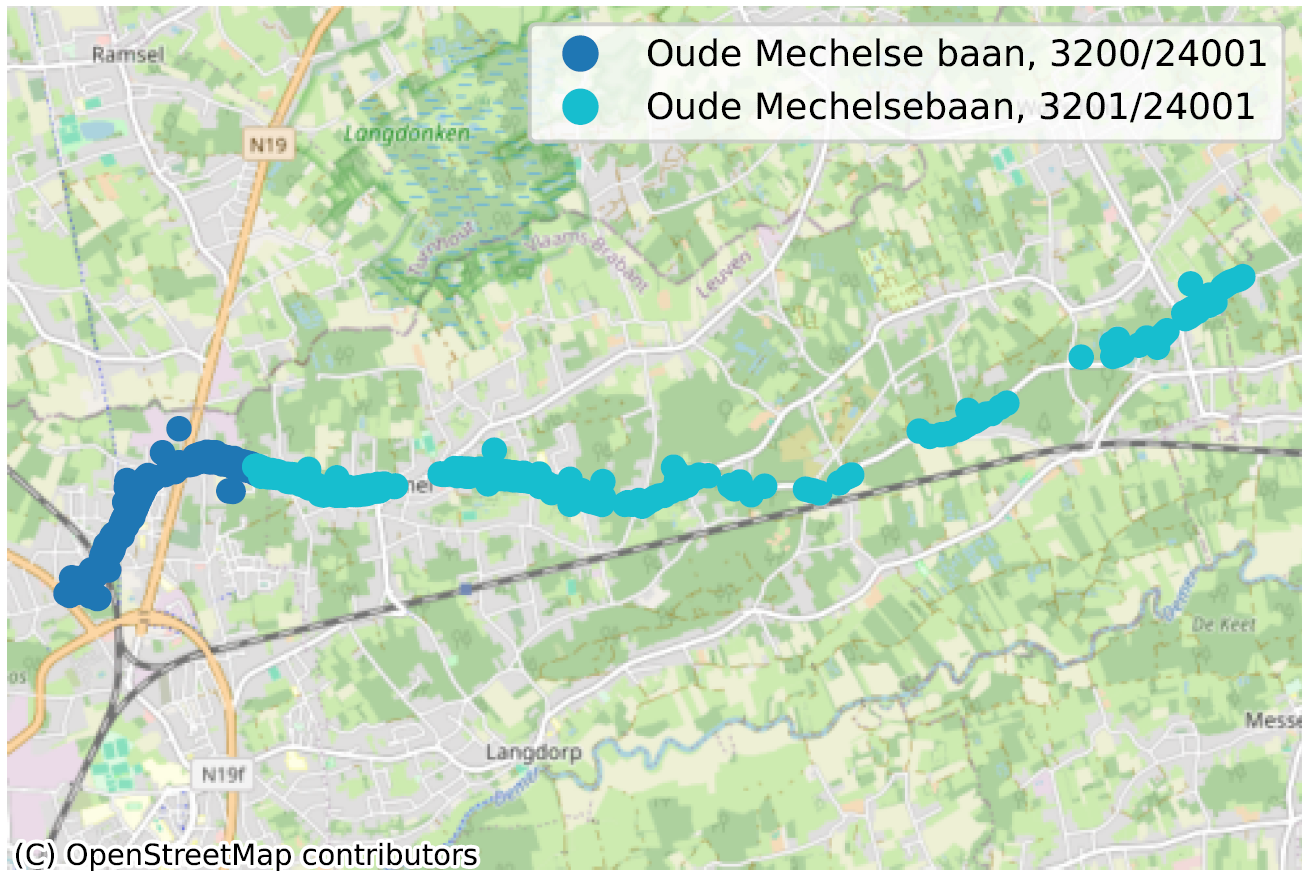
Inconsistente geometrie
Hier bekijken we de geometrische vorm die bestaat uit de opeenvolging van punten van adressen met dezelfde pariteit, voor dezelfde straat en postcode. Vervolgens berekenen we een aantal metrieken op deze lijn, ervan uitgaande dat de hoogste waarden duiden op een afwijking.
We hebben op experimentele basis een aantal metrieken gedefinieerd. We zullen er slechts twee nader toelichten waarvan we vonden dat ze het meest relevant waren voor de analyse. In een diepgaande analyse moeten ze echter worden gecombineerd met andere:
- delta_ratio: voor elk paar adressen in dezelfde straat en van dezelfde pariteit berekenen we de verhouding van het verschil tussen het numerieke deel van de huisnummers en de afstand. Een hoge waarde geeft aan dat twee huizen met zeer verschillende huisnummers abnormaal dicht bij elkaar liggen. Dit is vaak te verklaren door twee verschillende fenomenen:
- Normale situatie: een “cirkelvormige” straat, waarin het laatste nummer naast het eerste staat,
- Abnormale situatie: op de hoek tussen twee straten is een gebouw toegewezen aan de verkeerde straat. Of, meer algemeen, een inversie tussen twee nummers;
- prev_to_prev²_ratio: over het algemeen wordt verwacht dat een getal dichter bij het volgende getal (van dezelfde pariteit) ligt dan het getal dat daarop volgt. Indien nummer 2 veel dichter bij nummer 6 ligt dan bij nummer 4, is het waarschijnlijk dat nummer 4 op de verkeerde plaats staat. Hier berekenen we de ratio tussen de afstand tussen een nummer en het vorige nummer (bijvoorbeeld tussen 4 en 6) en de afstand tussen dat nummer en het nummer ervoor (bijvoorbeeld tussen 2 en 6). Een waarde van 100 geeft dus aan dat een getal (aangegeven met een ‘hn:…’ in de titel van de grafiek) 100 keer dichter bij twee nummers achter ligt dan bij het vorige nummer.
De eerste metriek zal adressen uitlichten die zich in de juiste straat bevinden, maar niet op de juiste plaats. De tweede geeft adressen aan die ver verwijderd zijn van andere nummers in dezelfde straat.
In de volgende illustraties zijn de stippen opeenvolgend gekleurd volgens de numerieke waarde van het huisnummer, gaande van paars voor de laagste waarde tot geel voor de hoogste. Een lijn verbindt deze stippen in numerieke volgorde.
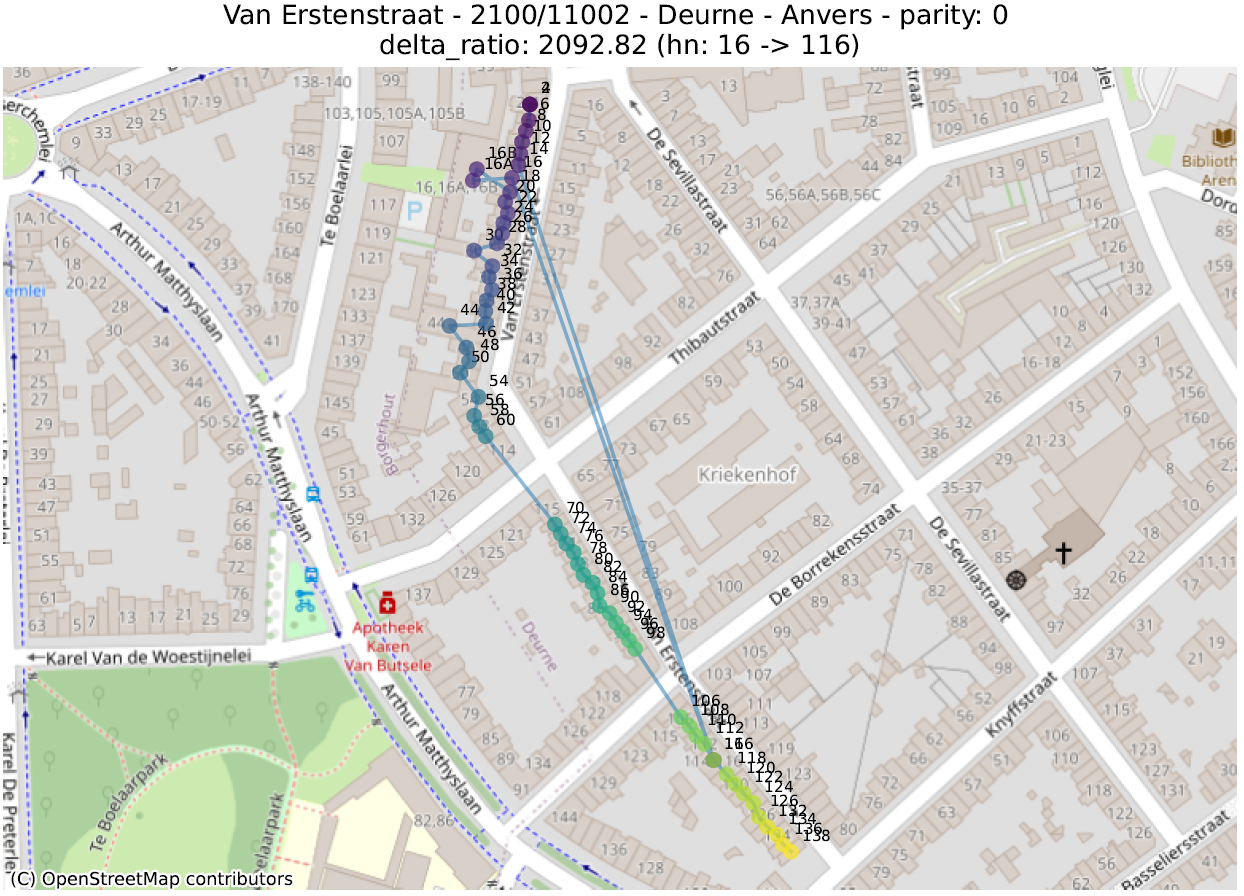
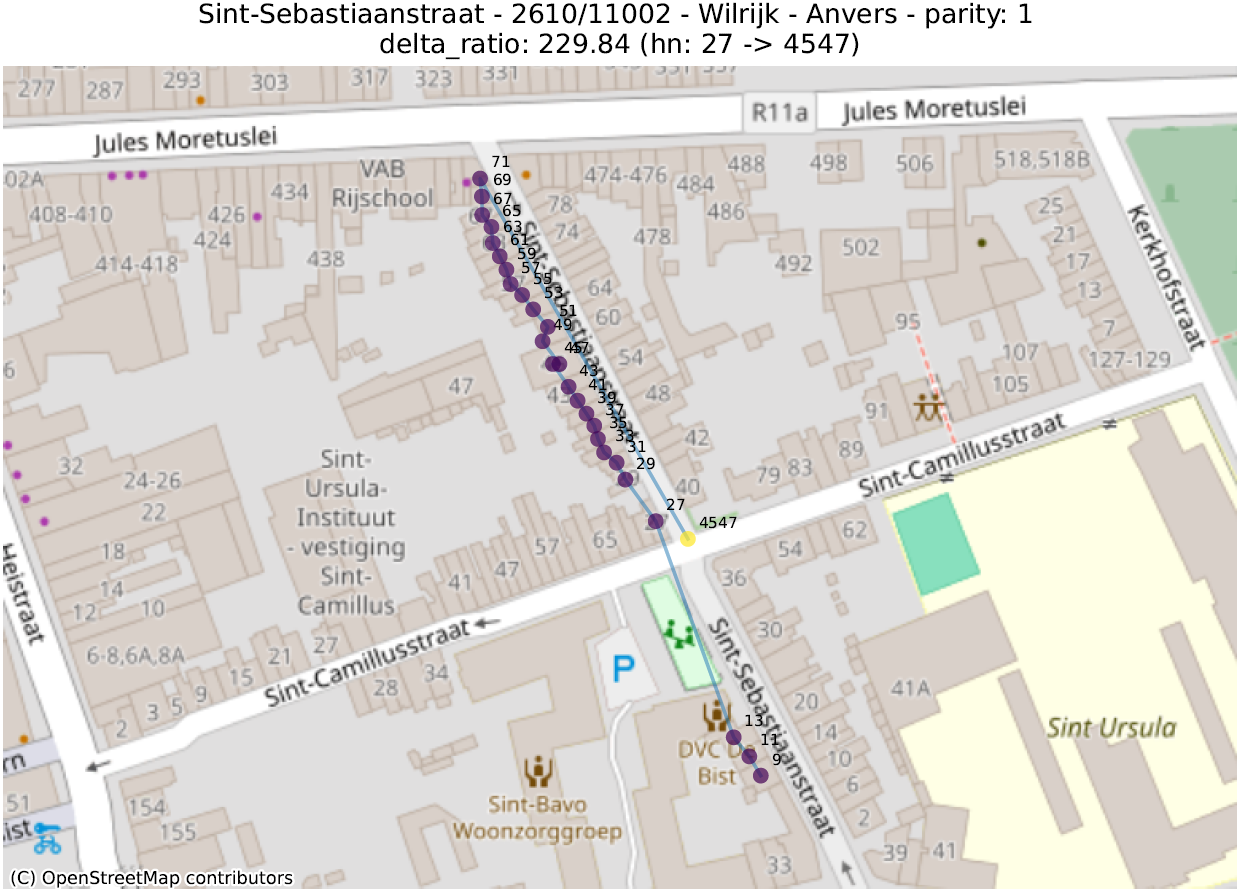
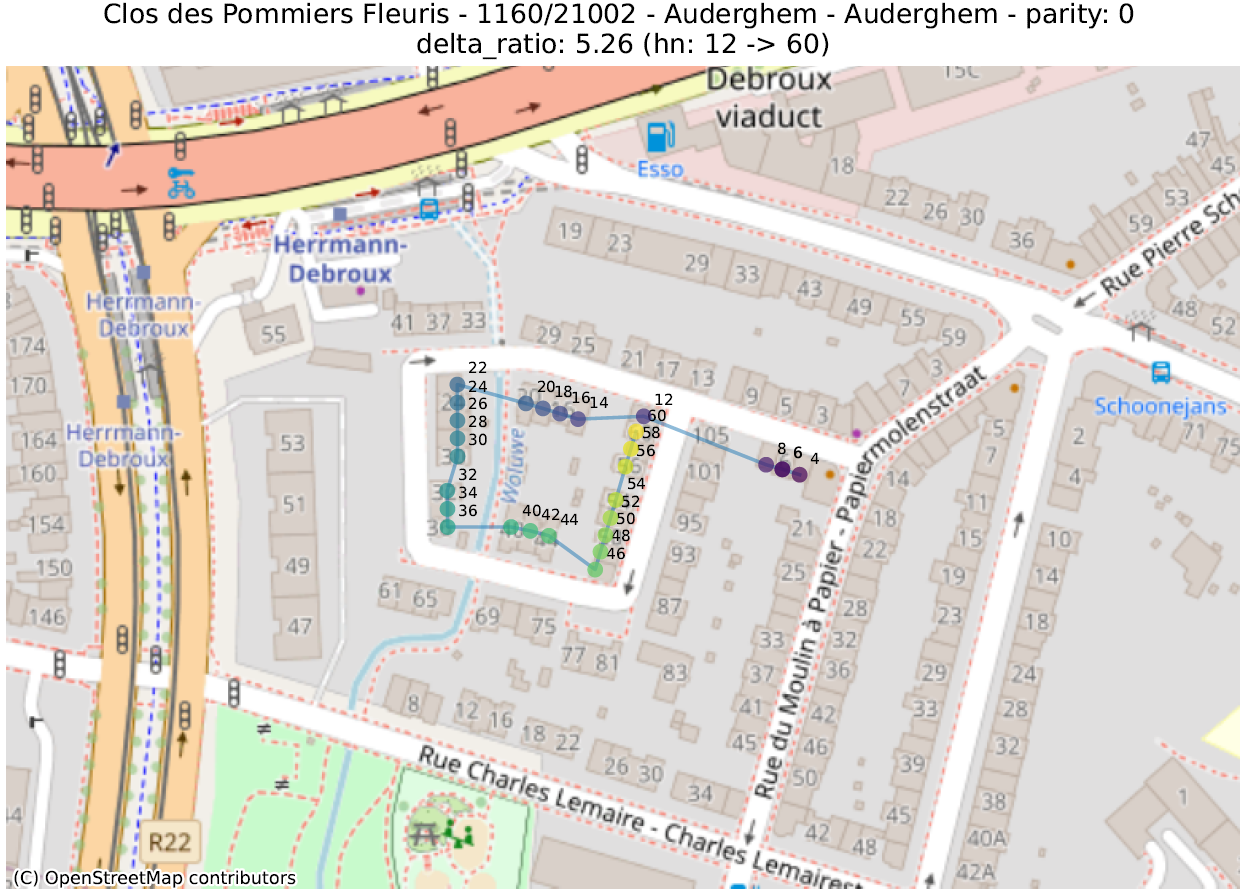
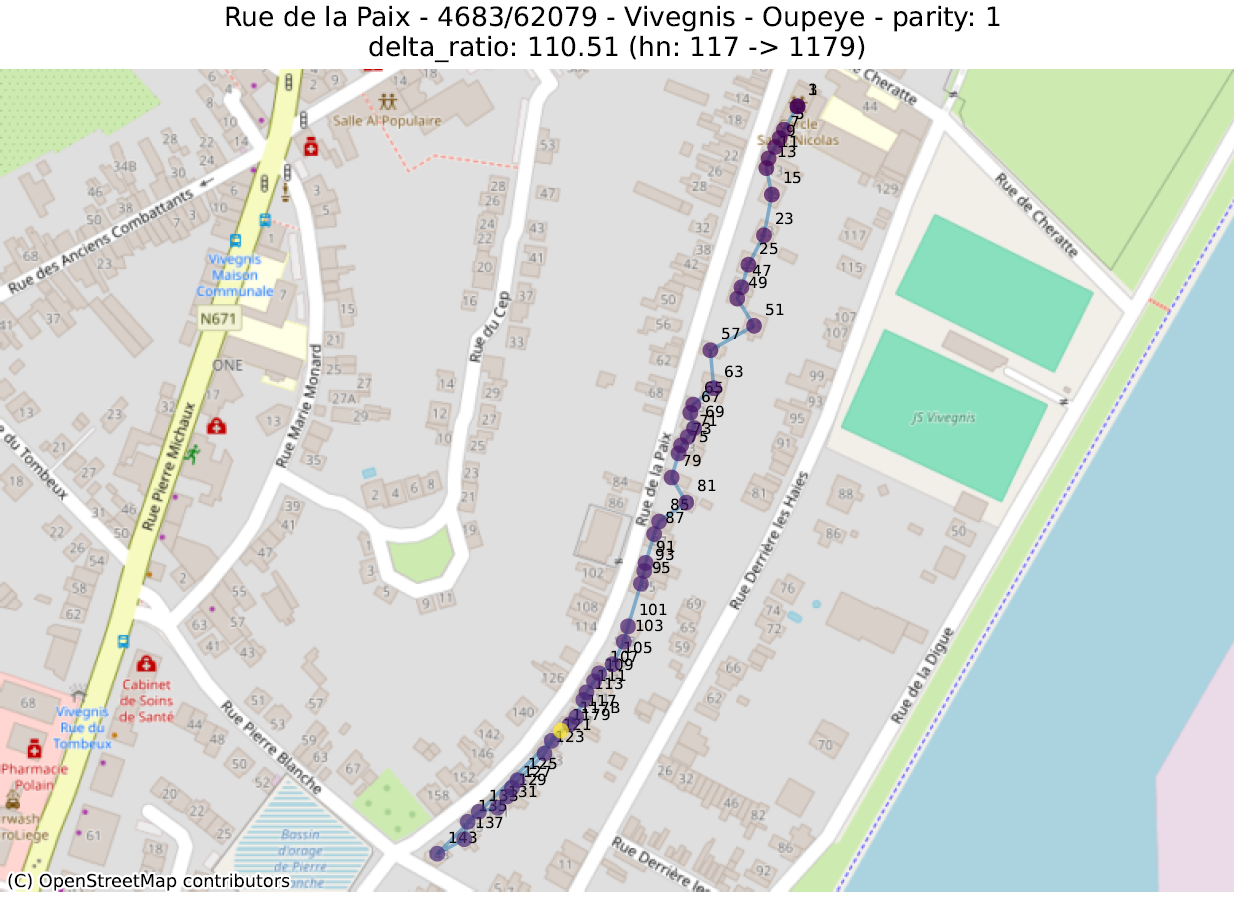
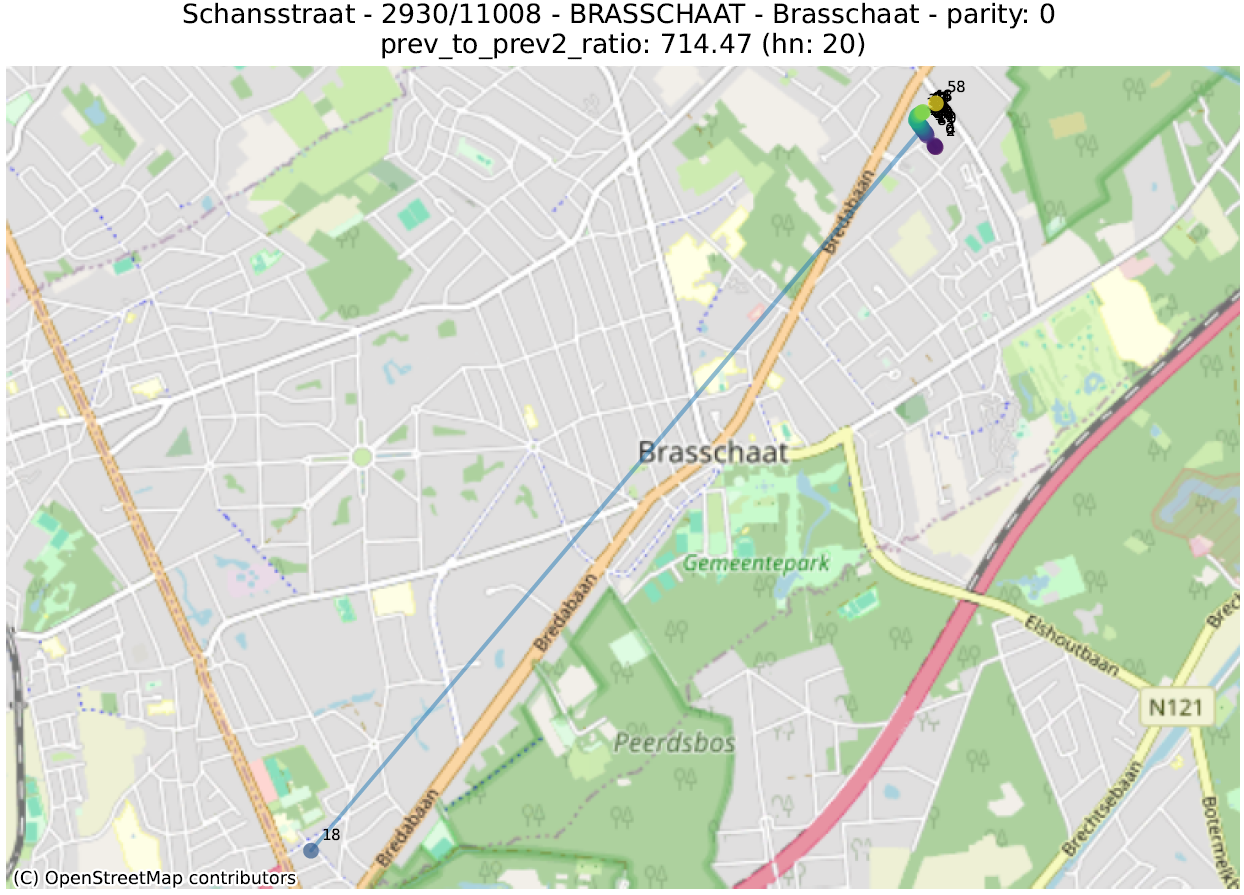
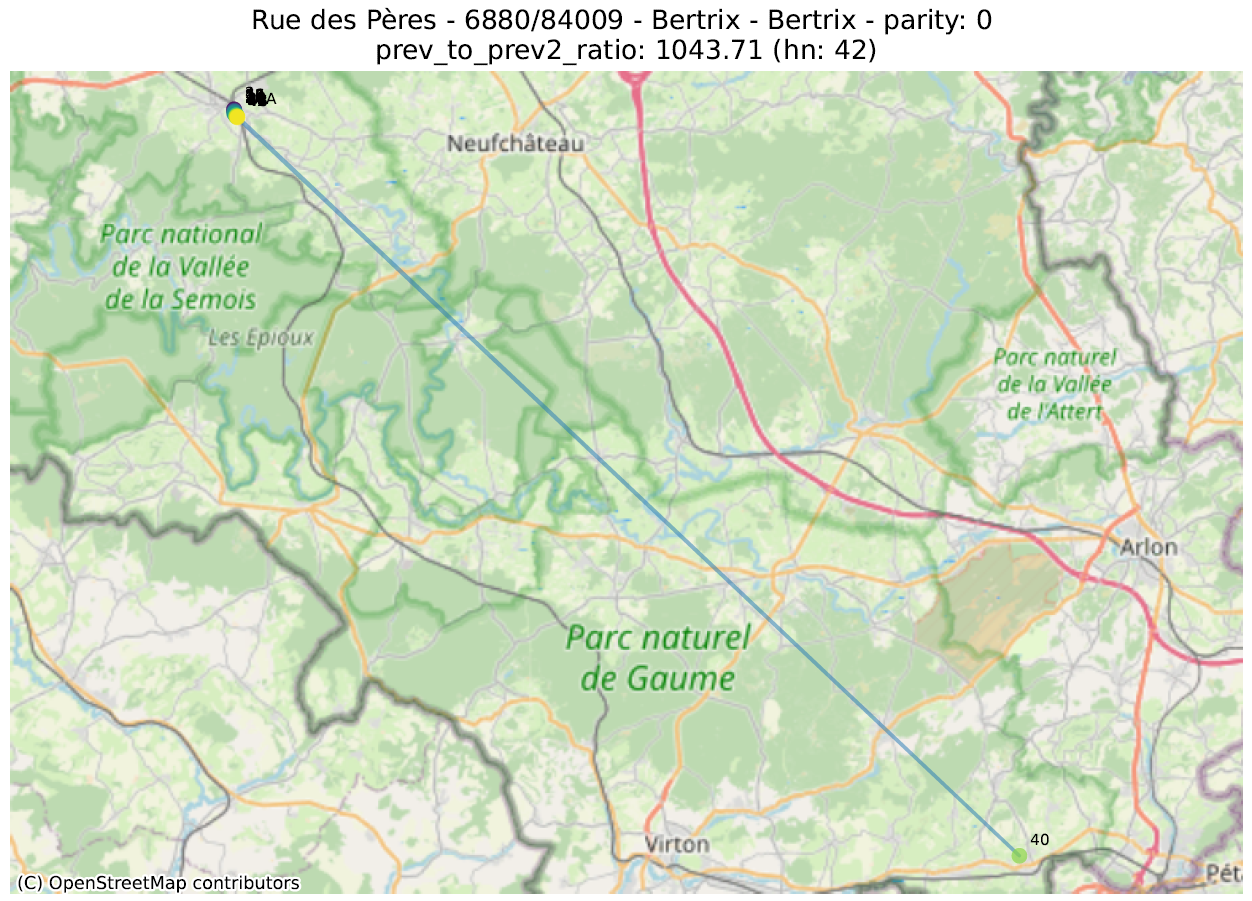
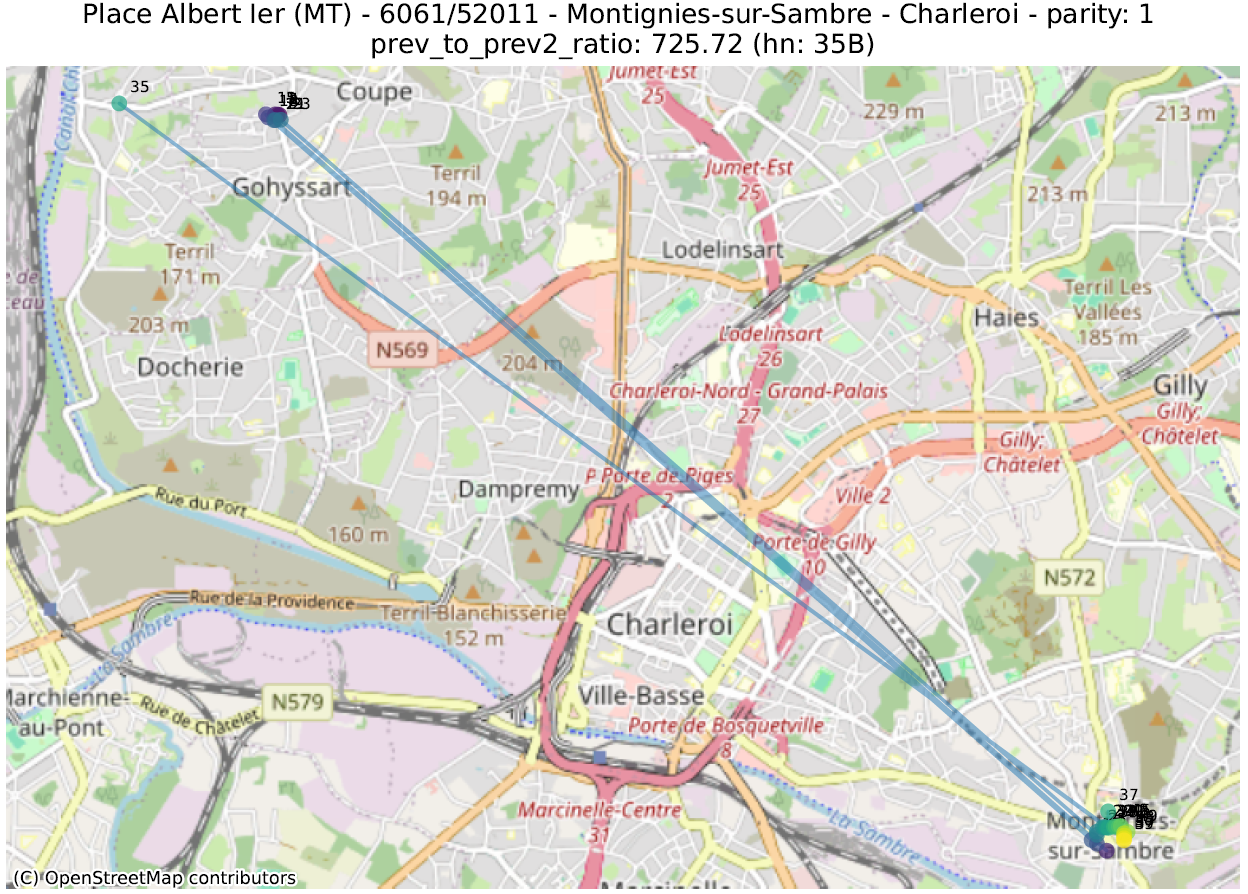
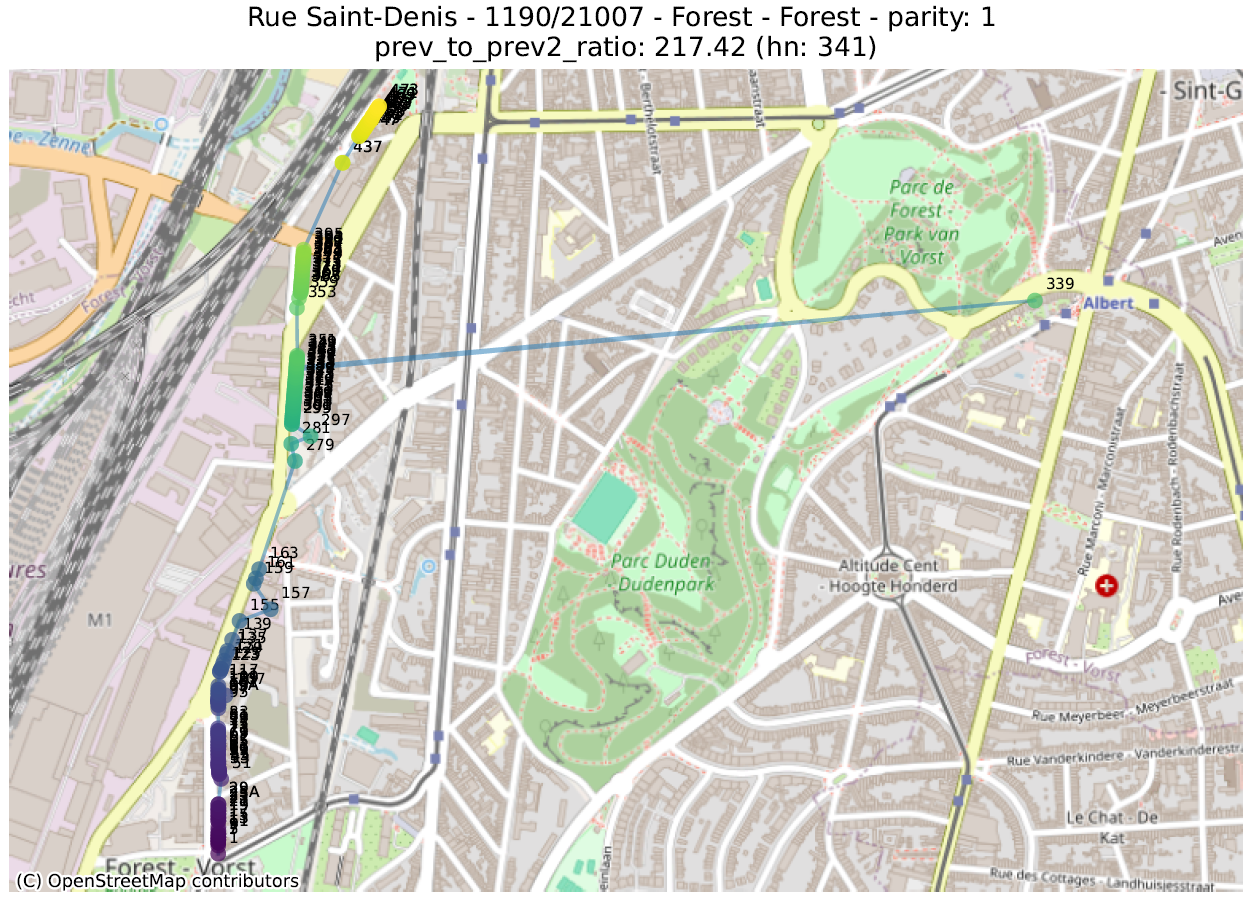
De analyse van deze anomalieën moet vaak van geval tot geval worden bekeken, om te bepalen of het om een duidelijke fout gaat of om de weerspiegeling van een enigszins ongebruikelijke bepaling. Dit werk kan enkel uitgevoerd worden door de lokale overheden, die de informatie doorgeven aan de gewesten en vervolgens aan het FOD BOSA.
Het slotwoord
De code (Python-notebook) waarmee we al deze anomalieën hebben geïdentificeerd, is beschikbaar op Github en biedt een interactieve weergave van alle kaarten die hierboven zijn gepresenteerd. Het is niet aan ons om voor elk van de anomalieën te bepalen of het werkelijk een fout is (er zullen veel fout-positieven zijn), en zo ja, op welk niveau het zich voordoet: de gemeente, de consolidatie door de regio’s of het FOD BOSA, bpost, het straatnaambord, enz.
Bovendien blijft het aantal probleemgevallen klein in vergelijking met de 6,5 miljoen adressen in BeSt Address. Toch vonden we de methodologie interessant genoeg om te publiceren. Ze zou ook kunnen worden toegepast op andere datasets, zoals OpenStreetMap of andere open bronnen.
Hoe een databank ook wordt gevuld, er sluipen altijd fouten in. De gewesten en de FOD BOSA verrichten al bergen werk om ervoor te zorgen dat de gegevens van zeer hoge kwaliteit zijn. Het zal echter altijd mogelijk zijn om nieuwe problemen op te sporen. Met dit artikel hopen we zelf een klein steentje bij te dragen.
Deze post is een individuele bijdrage van Vandy Berten, gespecialiseerd in data science bij Smals Research. Dit artikel is geschreven onder zijn eigen naam en weerspiegelt op geen enkele wijze de standpunten van Smals.
Leave a Reply