Data ingestion is het proces waarbij data uit verschillende bronnen worden verzameld en geïmporteerd in een gecentraliseerd opslagsysteem (datawarehouse, data lake, vector store, etc.) met het oog op gebruik voor specifieke doeleinden. Data kunnen uit verschillende bronnen komen, zoals databases, PDF/Excel/xml-bestanden, logbestanden, API’s en evenementen of websites. Het ingestion-proces moet waarborgen dat de data correct en volledig zijn en in bijna realtime beschikbaar zijn om bedrijfsanalyses te ondersteunen.
Hoewel de traditionele ingestion-methodes bekend zijn, heeft het gebruik van data om grote taalmodellen (LLM’s) te voeden een aantal specifieke kenmerken. In dit artikel bespreken we de ingestion van voornamelijk ongestructureerde data om de knowledge bases op te bouwen waarop generatieve AI-toepassingen zoals chatbots zijn gebaseerd.
Beschrijving van een data ingestion pipeline
De hieronder weergegeven pipeline [Representatie van een ingestion pipeline in een systeem voor question answering] is van toepassing op een RAG-systeem (Retrieval-Augmented Generation) voor het genereren van antwoorden op vragen op basis van een knowledge base. De knowledge base wordt gevoed door verschillende databronnen die de pipeline doorlopen, van verzamelen tot indexeren in een vector database. De voornaamste stappen in deze pipeline zijn de volgende.
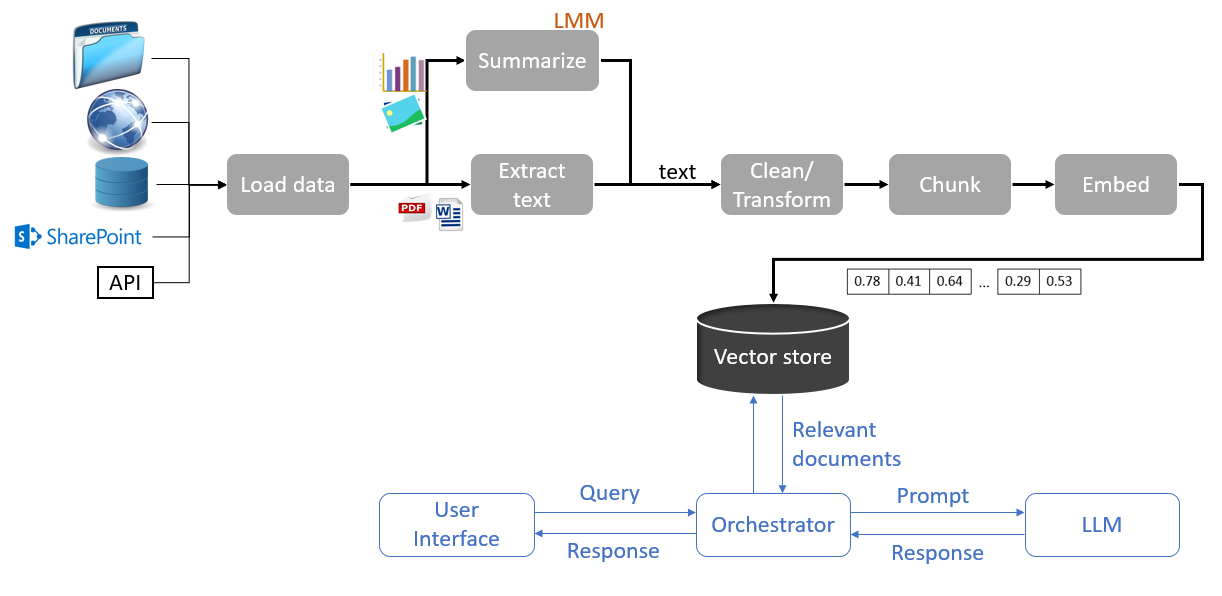
Data laden
De belangrijkste stap bij het bouwen van een ingestion pipeline voor een bepaald project is het identificeren van de databronnen die nodig zijn om dat project te voltooien. De input die gebruikt wordt in RAG-projecten bestaat voornamelijk uit ongestructureerde data uit verschillende bronnen, zoals websites, sociale netwerken, locale directories, databases, content management tools (bijv. SharePoint, Confluence), en opslagdiensten (bijv. S3). Voor elk van de gebruikte bronnen is het essentieel om over de juiste connectoren te beschikken en te controleren of je de benodigde toegangsrechten hebt.
Extractie
Zodra de bronnen zijn geïdentificeerd en de connectoren zijn geconfigureerd, kan de extractie van de inhoud beginnen. Het extractieproces hangt af van de databron en het dataformaat. Als de databron een webpagina is, moet een scrapingtool worden gebruikt om de HTML-inhoud te extraheren, waarna de inhoud moet worden geanalyseerd om de relevante informatie te extraheren. Als de databron een afbeelding is, moet je misschien een OCR-tool gebruiken, terwijl je voor databases de juiste SQL-query’s moet schrijven.
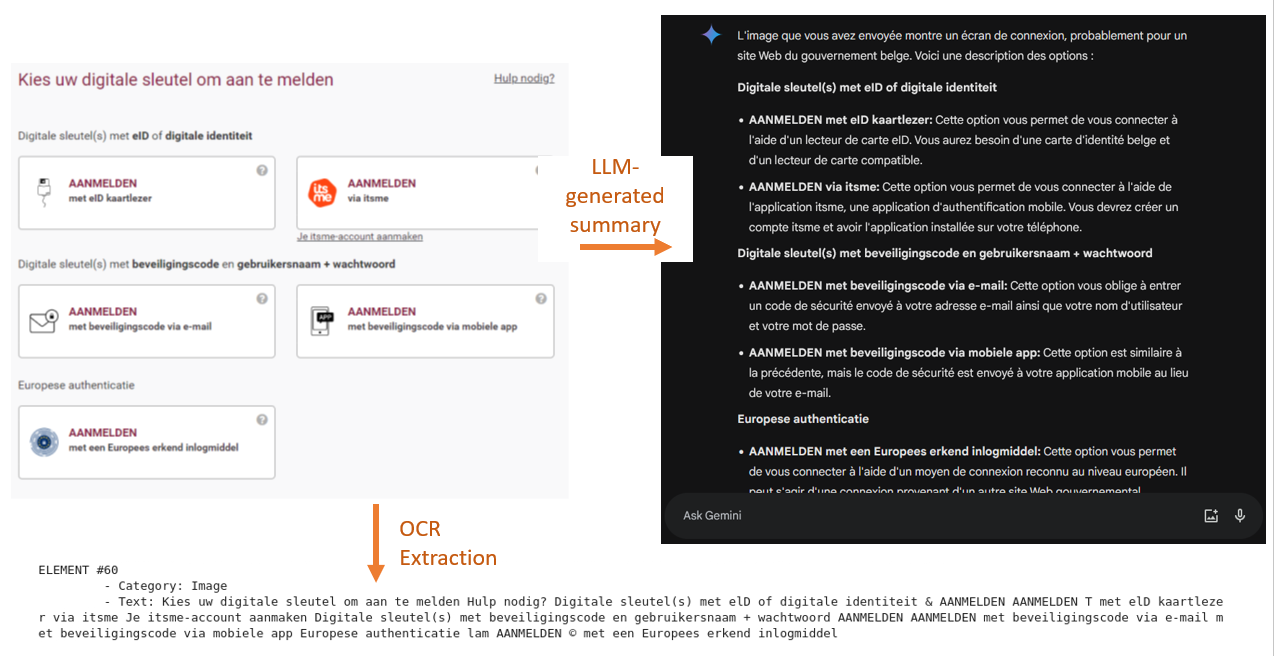
De inhoudsextractie kan gecombineerd worden met een inhoudsverrijkingsproces om metadata te genereren. Deze metadata worden uit de databron zelf gehaald (bijv. documentnaam, auteursnaam, URL, aanmaak- en wijzigingsdatum, tags) of uit de inhoud zelf (koptekst, titel, XML-tags). Een andere methode voor dataverrijking bestaat uit het gebruik van generatieve modellen om de beschrijvingen van afbeeldingen en tabellen in de data te genereren.
Ongeacht het formaat van de originele data, moet het resultaat van het extractieproces gestandaardiseerd zijn. Over het algemeen bestaat het uit tekst en bijbehorende metadata in JSON-formaat.
Opschonen en transformeren
Data geëxtraheerd uit bronnen is zelden bruikbaar zoals het is, en moet opgeschoond worden. Het opschonen is de meest tijdrovende fase en varieert afhankelijk van de use case. De meest voorkomende operaties die worden toegepast op inhoud zijn de volgende:
- Opschonen van leestekens en speciale karakters.
- Verwijderen van duplicaten.
- Verwijderen van onnodige informatie, zoals reclamebanners en cookies in inhoud van websites die ruis introduceren in de data.
- Controleren en corrigeren van tegenstrijdige, inconsistente of valse informatie, die het antwoord dat aan de andere kant van de RAG-procesketen wordt gegenereerd sterk beïnvloedt.
- Verwerken van ontbrekende informatie. Enkele voorbeelden van ontbrekende informatie in ongestructureerde data zijn links naar andere webpagina’s met aanvullende informatie op de geëxtraheerde inhoud, e-mails die verwijzen naar andere e-mails, enz.
Chunking
Chunking is het opsplitsen van tekst in kleinere eenheden. Hierdoor kan het model alleen die passages ophalen die informatie bevatten die relevant is voor het antwoord. Er bestaan verschillende chunkingmethoden, die kunnen worden gegroepeerd in twee categorieën: chunking op basis van vooraf gedefinieerde regels (vaste grootte, per alinea) en chunking op basis van semantiek (groepering van gelijksoortige segmenten). Efficiënt chunken bestaat uit het vinden van de juiste balans tussen wachttijd en kosten. Hoe kleiner de chunk, hoe meer opslag er nodig is en hoe hoger de latency; hoe groter de chunk, hoe groter de context van het model en dus hoe hoger de kosten. Welke methode ook gekozen wordt, het is belangrijk om rekening te houden met de structuur van de tekst en de maximale contextlengte van het taalmodel.
Genereren van vector database weergave (Embedding)
Dit is de fase waarin tekstdata wordt omgezet in vectoren waarop het semantisch zoeken specifiek voor RAG (retrieval) kan worden toegepast. Er bestaan verschillende embeddingstechnieken, maar de meest effectieve is de contextual embeddingstechniek gebaseerd op grote taalmodellen.
Indexering
Dit is de laatste fase in de ingestion pipeline. De data-output van de pipeline wordt geïndexeerd in een vector database zoals Weaviate, Pinecone, ElasticSearch, enz. Metadata wordt ook in de database geplaatst, zodat de resultaten kunnen worden verfijnd tijdens het zoeken (retrieval). De keuze van de Vector databases en het type indexering hangt af van het volume van de op te slaan data en de vereiste prestaties.
Andere aspecten om te overwegen
Batch of streaming ingestion
In batchmodus worden data massaal opgenomen met regelmatige tussenpozen of op aanvraag.
In streamingmodus worden nieuwe data direct in realtime of bijna realtime opgenomen. De streamingmodus wordt gekozen als de meest actuele informatie nodig is en als deze informatie snel verandert. Streaming ingestion vereist constante controle om de kleinste verandering in de datastructuur te detecteren.
Updates beheren
Om updates te beheren, is de traceerbaarheid van data belangrijk. Dit houdt in dat informatie zoals bron, versie, tijdstempel, laatste wijzigingsdatum, enz. wordt bijgehouden. Er zijn twee mogelijke strategieën voor het beheren van updates in bestemmingsdatabases: incrementeel updaten (alleen data die veranderd is wordt opgenomen) of volledig updaten. De veelheid aan databronnen en -formaten die worden gebruikt door LLM-gebaseerde toepassingen introduceert tal van problemen die ofwel te wijten zijn aan slecht beheer van de data bij de bron, of aan slechte tracering van wijzigingen door de dataverbruiker.
Beheer van de veiligheid
Zoals bij alle systemen die data verwerken, is er een minimum aan veiligheidsmaatregelen van toepassing op het ingestion proces:
- Toegang tot bronnen controleren.
- De juiste toegangsrechten toekennen wanneer inhoud wordt ingevoegd in de doeldatabase.
- Beveiligen van dataoverdracht tussen de bron en het ingestion systeem om knoeien met data (data tampering) te voorkomen.
- Enz.
Bij RAG-toepassingen worden persoonsgegevens regelmatig aangetroffen in niet-gestructureerde documenten. Deze gegevens vereisen bijzondere aandacht, omdat ze onderhevig zijn aan strikte regelgeving (GDPR). Gegevens moeten vaak worden geanonimiseerd voordat ze worden ingevoegd in de bestemmingsdatabase. Daarom is het noodzakelijk om een filterfase in te bouwen voor persoonlijk identificeerbare gegevens of PII filtering in de pipeline. Doeltreffende tools bestaan, maar ze garanderen geen 100% correcte filtering.
Een ander aandachtspunt specifiek voor RAG is de keuze van betrouwbare bronnen. In veel geavanceerde RAG-toepassingen wordt informatie uit websites gehaald. Een good practice is om de toepassing te beperken tot een lijst van vooraf gedefinieerde websites die kunnen worden opgevraagd.
Monitoring en foutenbeheer
Bij elke stap van de pipeline moeten fouten worden geregistreerd in logboeken en moeten waarschuwingssystemen worden ingesteld.
De algemene evaluatie van het ingestion systeem gebeurt indirect door de prestaties van het RAG-systeem te monitoren. Een slechte antwoord kan te wijten zijn aan een gebrek aan informatie in de database (de bronnen opnieuw evalueren), slechte chunking ( het gebruik van chunks en hun impact op de geleverde antwoord meten), enz….
Enkele bijzondere gevallen
RAG gecombineerd met web search
Typisch zijn de informatiebronnen die het vraag-antwoordsysteem voeden de knowledge base die wordt gevoed door de ingestion pipeline en de resultaten van web queries die on the fly worden uitgevoerd tijdens het verwerken van de vraag.
Het extractieproces wordt aangestuurd door het generatieve model (LLM) dat, afhankelijk van de query, de meest geschikte bron of een combinatie van de twee aanroept.
Multimodale RAG
Multimodale RAG maakt het mogelijk om data in verschillende vormen op te vragen: tekst, beeld, video en audio.
Er bestaan diverse strategieën om deze verschillende soorten data in te voeren:
- Gebruik van een referentiemodaliteit. Een modaliteit dient als referentie voor de datarepresentatie en de andere modaliteiten worden verankerd in deze referentiemodaliteit met behulp van specifieke modellen. In het hierboven weergegeven pipeline-voorbeeld is de referentiemodaliteit tekst en wordt voor elk beeld in de data een tekstuele samenvatting gegenereerd die dat beeld weergeeft.
- Gebruik van een multimodaal model. Een enkel multimodaal embeddingmodel wordt gebruikt om vectorrepresentaties van alle soorten data te genereren.
Tools
De keuze van een ingestion-platform hangt af van de complexiteit van het proces, het volume van de verwerkte data, de vereiste verwerkingssnelheid en de beschikbare bron- en bestemmingsconnectoren.
- Airbyte. Engine voor gestructureerde en ongestructureerde data-integratie die wordt gebruikt om datawarehouses of data lakes te voeden.
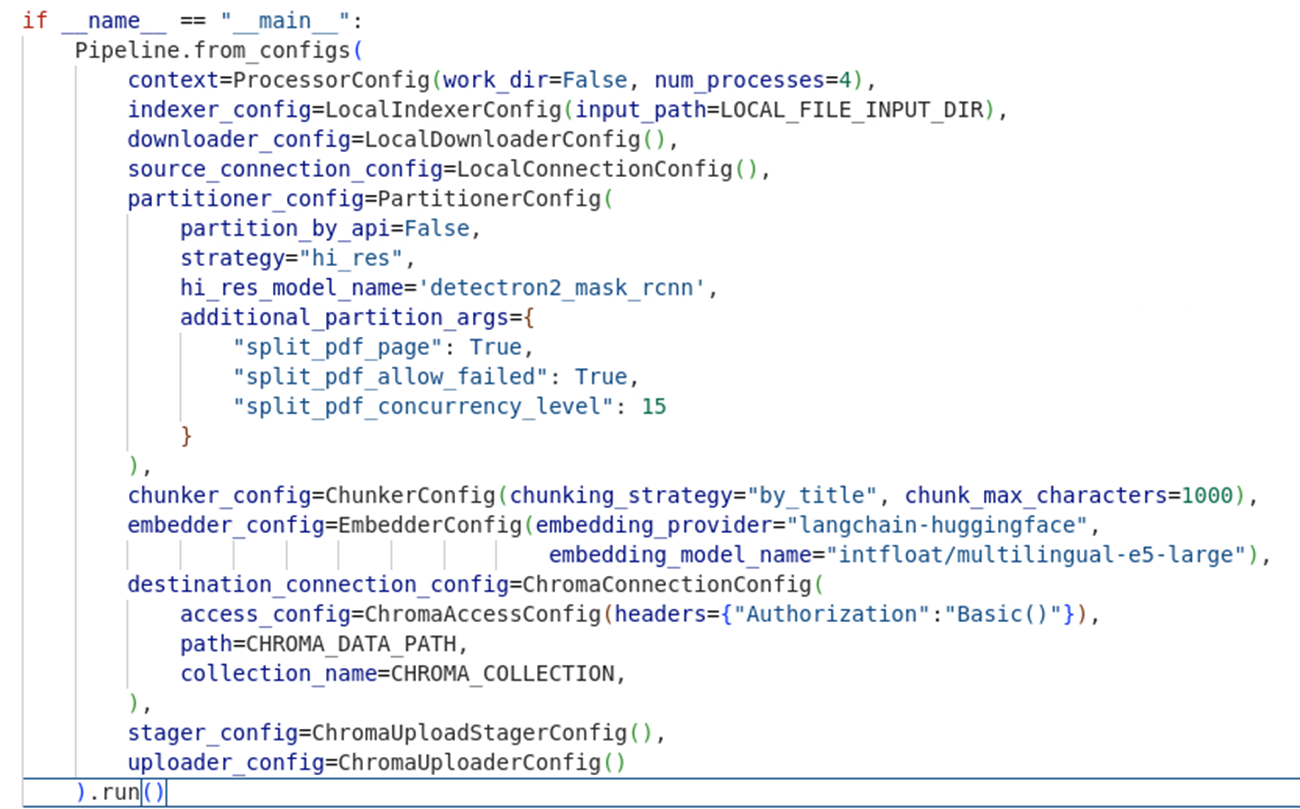
- Unstructured. Tool voor het bouwen van data pipelines voor LLM’s [Hier vindt u een link naar een quick review die wij over deze tool geschreven hebben].
- Langchain. Bijzonder veelzijdige tool voor het ontwikkelen van toepassingen op basis van generatieve AI, integreert met tal van databronnen en het Unstructured-platform, biedt tal van chunkingfuncties.
- LlamaIndex. Tool voor het ontwikkelen van toepassingen op basis van generatieve AI voor het doorzoeken van knowledge bases. LlamaIndex biedt ook een service voor het beheer van LLamaClouddata pipelines.
- Ray. Python library voor het beheren van gedistribueerde computerprocessen.
- Data ophalen van een webpagina: BeautifulSoup (Python library), Playwright, FireCrawl.
- Presidio: Filteren van persoonsidentificerende gegevens.
Conclusies
Data ingestion is een kritieke stap bij de ontwikkeling van een toepassing gebaseerd op generatieve AI omdat, zoals het gezegde luidt, “garbage in, garbage out”. Het bovenstaande artikel presenteert enkele technieken en best practices voor data ingestion; elke toepassing heeft echter zijn eigen specifieke kenmerken en moeilijkheden, die grotendeels afhangen van het toepassingsdomein van de oplossing. Daarom moet de ontwikkeling van een data ingestion-strategie het resultaat zijn van een nauwe samenwerking tussen een technisch expert en een domeinspecialist.
Leave a Reply