
Event Driven Architecture (EDA) is niet meer weg te schrijven uit moderne software-architectuur. Maar wanneer ben je nu effectief EDA aan het gebruiken? Soms kan het zijn dat dit paradigma in je software-systeem zit, zonder dat je er erg in hebt. En daarnaast gebeurt het ook vaak dat een architect zegt dat zijn systeem EDA gebruikt, maar dat de toehoorders zich daar iets heel anders bij voorstellen dan wat die architect eigenlijk bedoelt. Meestal ontstaat deze verwarring doordat er een aantal verschillende patronen bestaan, die allemaal onder dezelfde noemer van EDA vallen. In deze blog laten we ons licht schijnen op de 4 belangrijkste vormen van EDA.
Alle 4 deze vormen van EDA, zullen natuurlijk gebruik maken van de basis: een set van Event producers kan Events genereren en aan een of ander kanaal geven, waarna de Events worden afgeleverd aan een set van Event consumers. Zowel producers als consumers communiceren enkel met het kanaal (typisch een Event Broker) en hoeven elkaar voor de rest niet te contacteren (althans wat het versturen en ontvangen van de Events betreft).
Event Notification
De eerste manier om aan EDA te doen is de meest eenvoudige: een Event wordt hier simpelweg verstuurd om aan te geven dat er iets is gebeurd. Bijvoorbeeld een ‘CustomerChangedEvent’ om aan te geven dat er iets werd aangepast aan een klantenfiche, of een ‘OrderPlacedEvent’ om aan te geven dat er een nieuw order is.
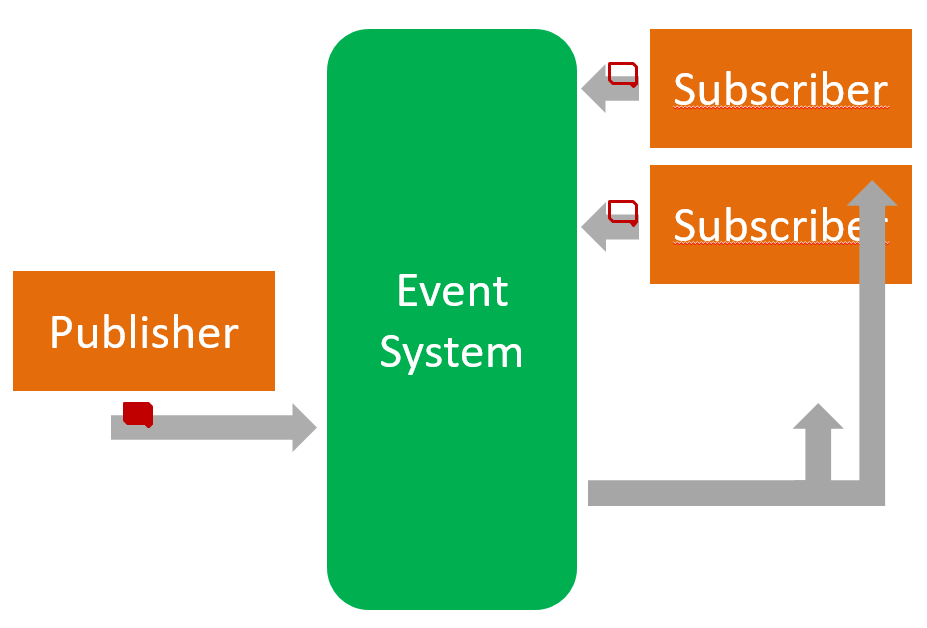
Belangrijk in dit patroon, is dat de Events verder geen toestand bevatten. Als de ontvangers van het event dus willen weten wát er precies is veranderd aan de klantenfiche, of wát er besteld werd in het order, dan zullen ze toch actief initiatief moeten nemen om aan deze informatie te geraken. Typisch zullen er dan, na het ontvangen van een event, API calls moeten worden gedaan naar het systeem dat rond de bron van het Event ligt, om meer details te bekomen.
De voordelen van dit patroon liggen voornamelijk in de eenvoud ervan: de Events zijn heel erg ‘lightweight’ en eenvoudig te implementeren. Een ander voordeel is dat het systeem dat Events verstuurt, niet hoeft te weten welke systemen er allemaal in de informatie zijn geïnteresseerd: ze zullen de informatie wel komen halen eens ze het Event ontvangen. Er wordt dus al een zekere mate van ‘louse coupling‘ en ‘Inversion of Control‘ bereikt.
Het nadeel van dit patroon is dat het aantal communicaties dat nodig is om bepaalde informatie te verspreiden naar de plaatsen waar ze nodig is, wordt verdubbeld: één keer om het Event te sturen, een tweede maal wanneer er extra informatie wordt gevraagd. Bovendien bestaat er nog steeds een afhankelijkheid in één richting, omdat de systemen die extra informatie nodig hebben, zullen moeten weten waar ze te gaan halen.
Het zal niet verbazen dat deze eenvoudige manier van werken met Events, met overwicht nog steeds de meest gebruikte vorm is, en dat, wanneer er wordt gezegd “ons systeem maakt gebruik van EDA”, er dus meestal Event Notification wordt bedoeld. Dit is echter lang niet de meest krachtige en voordelige manier om van het paradigma gebruik te maken…
Event-Carried State Transfer
Deze tweede manier van werken is de gouden middenweg tussen het toepassen van de volledige kracht van EDA, en het loslaten van de bijhorende complexiteit op een systeem. Het is ook hetgeen de echte voorstanders van EDA begrijpen, wanneer ze van een architect horen dat het paradigma wordt toegepast.
De naam Event-carried State Transfer (EST ?) is gekozen om een beetje te contrasteren met REST (Representational State Transfer). Er is dus sprake van het overbrengen van toestand, t.t.z. effectieve gegevens, tussen systemen. Als we het vorige voorbeeld hernemen, dan zal er aan het CustomerChangedEvent effectief zijn toegevoegd wát er precies is veranderd: minimum wat het nieuwe gegeven is, eventueel ook wat het oude gegeven was, en mogelijks zelfs een hele resem extra gegevens over de klant. Dit vormt meteen ook de moeilijkste evenwichtsoefening bij het ontwerp: hoeveel data zullen we precies toevoegen aan het Event? De bedoeling is natuurlijk dat de ontvanger van het Event alles heeft wat er nodig is om verder te kunnen, zonder nog extra gegevens te moeten gaan opvragen.
De voordelen van dit patroon zijn uiteraard precies de nadelen van het vorige: als het Event het juiste ‘gewicht’ heeft, kan extra communicatie tussen alle partijen worden vermeden, en zijn de systemen dus bijgevolg ook wederzijds onafhankelijk van elkaar: ze hoeven enkel nog met het kanaal te praten via welke Events worden beheerd. Elk systeem kan direct aan de slag met de juiste informatie die door het Event wordt aangeleverd.
Een bijkomend voordeel is dat de Events volgens dit paradigma een grotere mate van herbruikbaarheid hebben: men kan een catalogus aanleggen van Events die beschikbaar zijn in een ecosysteem van applicaties als primaire manier om gegevens over te brengen: een volwaardig alternatief voor RESTful APIs. Elke nieuwe applicatie die de aangeboden informatie kan gebruiken, kan zich dan inschrijven om het desbetreffende Event te ontvangen.
Nadeel is dat deze manier van werken met Events iets meer werk vraagt: men zal moeten nadenken over welke Events het meest nuttig zijn en hoeveel informatie deze best bevatten. Men zal de Events moeten opnemen in een catalogus, zodat ze optimaal worden hergebruikt. Daarnaast krijgt men soms wat overbodig dataverkeer omdat de Events mogelijks meer informatie bevatten dan de ontvanger nodig heeft. De architecturale complexiteit is echter slechts een weinig hoger dan bij Event Notifications (voor de applicties die Events versturen blijft het b.v. gewoon “iets extra doen op sommige momenten”).
Een laatste aandachtspunt is dat het inzetten van EDA om toestand te verspreiden overheen systemen de notie van Eventual Consistency neigt te activeren. Dit kan zowel voordelen als nadelen hebben.
Event-Carried State Transfer komt dan wel al wat vaker voor dan vroeger (en ligt ook meestal aan de basis van het populair geworden event streaming), maar er ligt nog heel wat onaangeroerd potentieel om met deze manier van werken grote voordelen te behalen in sommige applicatie-ecosystemen.
Event Sourcing
Nu komen we bij de echte kern van het paradigma, waarbij we radicaal voor EDA kiezen doorheen het volledige ontwerp van ons systeem. Waar de vorige manieren van werken nog weinig intrusief waren in de architectuur, is dit bij Event Sourcing niet langer het geval: de architectuur is nu volledig op Events gebaseerd.
Bij Event Sourcing zal een systeem niet meer op de normale manier zijn toestand gaan bepalen of bewaren, maar zal de huidige toestand steeds gezien worden als gevolg van het ontvangen van een reeks van Events, die elk een kleine toestandswijziging teweegbrengen. Je kan het zien als een bankrekening: het huidige saldo is simpelweg het resultaat van alle voorbije verrichtingen. Een ander goed voorbeeld betreft versiecontrolesystemen zoals git: bij zo’n systeem is de huidige toestand samengesteld uit alle voorbije ‘commits’. Er zijn nog heel wat meer zaken te vertellen over Event Sourcing, maar we bespraken deze manier van werken reeds uitgebreid in een aantal vorige blogs.
Het grote nadeel van Event Sourcing is de sterk verhoogde complexiteit van de software die volgens dit paradigma is gebouwd. Men zal dus goed moeten overwegen of de krachtige mogelijkheden die door het gebruik ervan ontstaan, deze complexiteit waard zijn. Het feit dat Event Sourcing zelden wordt gebruikt en er daardoor slechts weinig architecten voldoende ervaring mee hebben, maakt dit echter erger dan het zou moeten zijn: eens men deze andere manier van werken in de vingers heeft, kan men pas goed de voordelen ervan appreciëren.
De voordelen van Event Sourcing bevatten namelijk de voordelen van Event-carried State Transfer, en breiden deze nog uit: men heeft nu toegang tot de volledige geschiedenis van de applicatie, en niet enkel de huidige toestand. Hierdoor kan men stukken uit het verleden ‘terug gaan afspelen’, wat goed van pas kan komen bij testing en debuggen, of wat veel mogelijkheden geeft bij analytics van deze gegevens. Een event sourced systeem is door deze geschiedenis ook heel geschikt voor audit logs.
Bij gebruik van Event Sourcing kan men de applicatie zelfs ontwerpen zonder echte database: men kan de huidige toestand gewoon in het werkgeheugen plaatsen, zolang de Events zelf goed worden gepersisteerd. Bij falen kan men dan steeds de toestand terug opbouwen op basis van de Event Store (in de praktijk gecombineerd met snapshots van de toestand op geregelde tijdstippen).
Wanneer men al gebruik maakt van Event Sourcing, dan moet men ervoor opletten niet automatisch ook de volgende stap te nemen…
Command Query Responsibility Segregation
De meeste applicaties worden opgebouwd rond een CRUD (create, read, update, delete) systeem. Soms kan het echter interessant zijn om een applicatie op te splitsen in meerdere componenten: degene die schrijven naar de datastore en degene die er in gaan lezen. Je hebt hier dus verschillende modellen waarmee wordt gewerkt: één dat updates behandelt en één (of meerdere) dat queries behandelt. Deze opsplitsing noemen we Command Query Responsibility Segregation (CQRS). Ook CQRS bespraken we reeds in eerdere blogs.
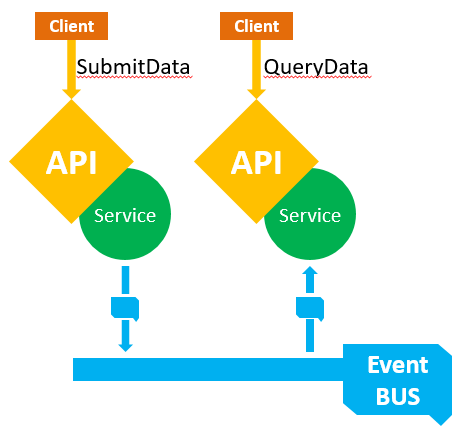
In theorie kan deze manier van werken zonder EDA, maar in de praktijk zullen Events altijd de beste manier vormen voor de communicatie tussen de verschillende subsystemen. Commando’s resulteren dan in Events met bepaalde inputs, die op hun beurt resulteren in Events betreffende toestands-wijzigingen. Query systemen die kort op de bal moeten spelen, schrijven zich in voor deze events en passen bij elk Event onmiddellijk hun uit te lezen toestand aan.
CQRS introduceert enorm veel complexiteit in een systeem. Het is dus zaak van te kijken of het echt serieuze voordelen kan opleveren. Sommige erg complexe business domeinen hebben baat bij deze opsplitsing, omdat het kan resulteren in een kleinere hoeveelheid logica per deelsysteem, indien dat deelsysteem is toegespitst op slechts één verantwoordelijkheid (update of query). In de meerderheid van de gevallen is er echter grote overlap tussen de logica voor updates en deze voor queries, waardoor het delen van een model efficiënter is. De principes van Domain Driven Design kunnen hier helpen.
Een andere reden om CQRS te gebruiken vinden we in performantie en beschikbaarheid: een systeem dat zelden wordt geüpdated en vaak queries krijgt (of omgekeerd) kan baat hebben bij het splitsen van deze verantwoordelijkheden, zodat de componenten apart kunnen worden geschaald (maar ook hier zijn er, naast CQRS, eventueel alternatieve architecturen mogelijk).
Kort samengevat: CQRS kan heel krachtig zijn, maar is ook erg complex. Use with Caution.
Conclusie
Nu we de vier voornaamste manieren hebben onderscheiden om gebruik te maken van Event Driven Architecture, zijn we in staat om preciezer te communiceren over het paradigma, en voor elk project een weloverwogen keuze te maken tussen de verschillende werkwijzen.
Event Notification kunnen we zien als beginnelingen-EDA, en is het makkelijkst toe te voegen aan een bestaand systeem. Het kan reeds meerwaarde brengen en de betrokkenen ‘opwarmen’ voor het echte werk. Event Carried State Transfer is een krachtiger mechanisme, met een complexiteit die nog goed onder controle blijft. Deze twee eerste methoden om Events te gebruiken, spelen vooral in op de interactie tussen verschillende systemen, en hebben iets minder invloed op de interne werking ervan.
De zaken veranderen wanneer we kijken naar Event Sourcing en CQRS. Deze paradigma’s werken echt in op de kern van de architectuur binnen een welbepaald systeem, en voegen een behoorlijke dosis complexiteit toe. In bepaalde gevallen is dit het echter waard, vanwege de krachtige en unieke voordelen die op deze manier worden verkregen.
_________________________
Dit is een ingezonden bijdrage van Koen Vanderkimpen, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply