Dans le secteur public, les administrations font face à un nombre considérable de documents à gérer. Ces documents doivent être indexés et organisés tel qu’il soit possible de retrouver facilement de l’information. Dans ce contexte le NER ou Named Entity Recognition, une technique basée sur le machine learning et le Natural Language Processing (NLP), est une solution particulièrement intéressante. Cela permet d’extraire automatiquement de l’information de documents textuels ainsi que audio et vidéo.
Le NER consiste à reconnaître des entités nommées (Named Entities) dans un corpus (ensemble de textes) et de leur attribuer une étiquette telle que “nom”, “lieu”, “date”, “email”, etc. Si le NER désigne au départ l’extraction de noms propres, de noms de lieux et de noms d’organisations, ce concept s’est étendu à d’autres entités telles que la date, l’email, le montant d’argent, etc. Dans bien des cas, il est utilisé pour extraire des termes propres à un domaine comme par exemple le numéro IBAN pour la gestion des paiements bancaires ou l’extraction de noms de gènes dans le domaine biomédicale.


Développé à l’origine pour la recherche d’information (information retrieval), le NER a aujourd’hui de nombreuses applications outre l’indexation de documents. Il est notamment utilisé dans les systèmes de questions-réponses (Q&A) qui consistent à répondre à une question posée en langage naturel en recherchant la réponse dans une collection de documents ou une base de connaissance. Pour cet usage, le NER peut s’avérer utile pour déterminer le type de réponse que le système Q&A doit retourner en se basant sur des entités retrouvées dans la question (ex. un lieu, une date).
Le NER peut aussi être utilisé en préalable d’autres tâches de NLP telles que l’annotation sémantique, la traduction machine, la classification ou pour alimenter une ontologie.
Comment implémenter un système NER ?
Il y a plusieurs approches pour l’implémentation d’un système NER. La première consiste à utiliser des règles prédéfinies (souvent des expressions régulières mais aussi des règles composées à partir d’ étiquettes morphosyntaxiques) ; les règles offrent l’avantage d’être rapidement implémentées mais leur portée est restreinte. Dans l’exemple ci-dessous, on utilise une expression régulière pour reconnaître un numéro de téléphone. On constate que, selon la structure du numéro de téléphone, celui-ci sera détecté ou non par le système NER. Il faut donc écrire des règles complexes pour couvrir tous les cas de figure.
Exemple de motif utilisé pour reconnaître un numéro de téléphone: “^0\d{1,3}\/\d{2,3}\.\d{2,3}(\.\d{2})?$”

Une autre approche consiste à utiliser des méthodes dites statistiques c.-à-d. le machine learning (apprentissage machine) et plus récemment le deep learning. L’avantage de ces techniques consiste à utiliser le contexte pour reconnaître une entité et lui attribuer une catégorie. Si l’on considère des noms tels que Bruxelles ou Pierre Dupont, on peut les détecter sur base de règles utilisant entre autres, la structure du mot et des éléments morphosyntaxiques mais il sera difficile de catégoriser les entités de façon correcte. L’utilisation du machine learning/deep learning requiert néanmoins un grand nombre de textes annotés manuellement pour l’entraînement et l’évaluation du modèle NER.
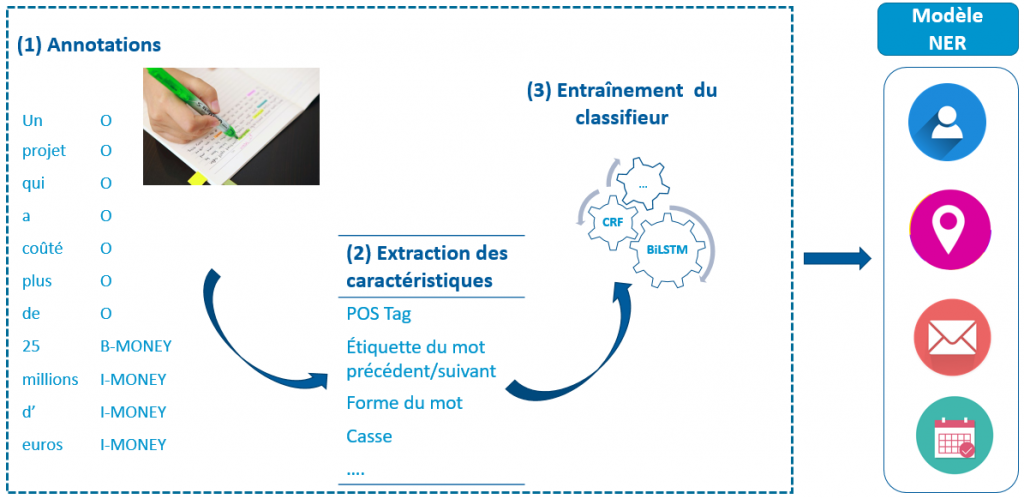
Dans la pratique, une implémentation de NER efficace est une combinaison de règles et de méthodes statistiques. Étant donné le coût en temps et en ressources nécessaire pour annoter des données et développer un modèle NER, on privilégiera autant que possible l’utilisation de règles formelles pour la détection d’entités.
L’implémentation d’un système NER et en particulier d’un système NER basé sur du machine learning/deep learning pose quelques défis:
- La langue. Pour l’application d’un modèle statistique, la langue d’entraînement de l’algorithme est déterminante. Il existe des outils NLP qui permettent de faire de la reconnaissance d’entités « out of the box » néanmoins la plupart ces outils NER sont principalement développés pour l’anglais et peu ou pas pour le français et le néerlandais.
- Le type de texte. Un modèle entraîné sur une structure de texte particulière n’est pas toujours transposable à d’autres types.
- Le type d’entité que l’on souhaite reconnaître
- L’ OCR. Le processus d’océrisation de documents non digitaux introduit des erreurs qui affectent les performances du NER.
- Les entités ambiguës. Les cas de métonymie et polysémie sont difficilement gérables. Ex. : dans la phrase « tout cela se décide à Bruxelles » parle-t-on de la ville ou de l’Union Européenne ?
- Très souvent, il y a peu de données disponibles pour entraîner le NER. Une solution parfois utilisée pour parer cette difficulté est l’apprentissage par transfert (transfer learning) . Le transfer learning consiste à prendre un modèle générique NER entraîné dans un domaine où on a beaucoup de données et de l’affiner sur un nombre limité de données dans le domaine d’intérêt.
- L’annotation manuelle du corpus est une tâche lourde, cependant il existe des outils qui permettent de l’exécuter de façon semi-automatique.

Application à un article de presse d’un modèle NER entraîné sur des textes Wikipédia.

Les résultats du NER sont donc loin d’être parfaits. C’est pourquoi dans une implémentation concrète, on le combine si possible avec une étape de validation. Dans l’exemple donné en introduction de ce blog, le module NER a identifié comme entité le mot « Diables » et l’a ensuite catégorisée comme lieu (LOC). Il est facile de vérifier l’existence d’une entité de ce type (LOC) en la comparant à une base de données géographiques telles que GeoNames ou OpenStreetMap.
Pour conclure, le Named Entity Recognition est une technique de traitement automatique du langage naturel (NLP) très utile pour le traitement et la gestion de documents. Si les entités sont très facilement reconnaissables dans un texte par un humain, l’automatisation de cette tâche ne se fait cependant pas sans difficultés. En pratique, on peut l’utiliser pour faciliter la recherche documentaire, pour le routage de courriers/documents électroniques vers les services adéquats, le paiement de facture automatique, l’enrichissement sémantique, etc.
____________
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
bonjour j’ai télécharger le modèle français de NER Spacy mais le modèle n’arrive pas a reconnaître les dates comme il est affiché dans votre article