In 2014 publiceerden we een research note over ‘Open Data’ naar aanleiding van de Europese richtlijn PSI (Public Service Information) van 2013 die van toepassing was in 2015 (1).
Sindsdien verschenen of verschijnen nog steeds andere Europese wetgevingen. Deze nieuwe wetten doen niets af aan wat van toepassing was in 2014 (afgezien van enkele url’s uit de research note van 2014 die niet meer up-to-date zijn) maar verbreden aanzienlijk het toepassingsveld (2) ervan dat we in dit blogartikel gaan voorstellen.
We komen hier niet meer terug op de definitie van ‘open data’, op hun mogelijk betalende aard (minieme kosten van de terbeschikkingstelling van een webservice, bijvoorbeeld in het geval van de KBO en databases van ondernemingen in het algemeen) of op de kwestie van licenties. We verwijzen de lezer hiervoor naar de research note van 2014.
Deze nieuwe reglementeringen zagen het licht in een context waarin nieuwe case study’s als gevolg van de verspreiding van open data tot positief gebruik hebben geleid. Een voorbeeld is het besluit eind 2023 om meteorologische gegevens in Frankrijk openlijk te publiceren om onderzoek en uitwisseling tussen onderzoekers aan te sporen “De instantie zal nieuwe technische mogelijkheden voor API’s invoeren om gratis toegang te krijgen tot haar observatiegegevens, klimatologische gegevens en radargegevens” (zie link hierboven). Zo hebben we sinds 2014 aangetoond in welke mate de terbeschikkingstelling van dynamische meteorologische en geografische gegevens in de VS, samen met het gebruik van social media, ervoor zorgde dat de gevarenzones tijdens een orkaan geïdentificeerd konden worden en hoe getroffen personen in contact kwamen met mensen die hun hulp aanboden (onderdak, etc.). Onderstaand schema toont het ideale circuit van ‘open data’ gaande van de verzameling tot het gebruik van de gegevens.
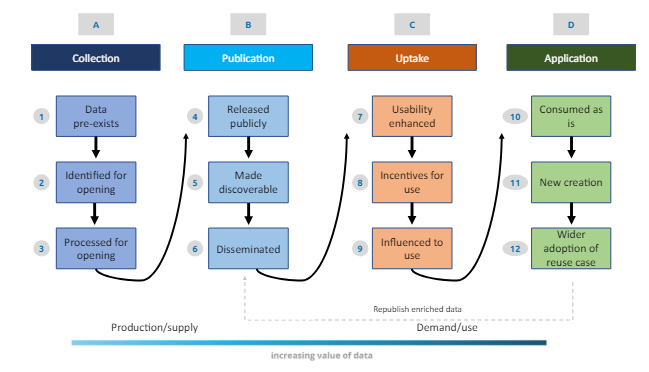
Bron: Open data value chain, adapted from Open Data Watch in Indicators for an Open Data Impact Assessment (UE)
Verder in dit blogartikel bekijken we:
- vier wetgevingen (een richtlijn en drie verordeningen)
- de uitdaging van kwalitatieve gegevens en de ROI van open data
Richtlijn PSI 2019 (van toepassing in 2021, omgezet in de Belgische wetgeving in december 2023)
Deze richtlijn impliceert de integratie van de volgende nieuwe elementen in het Belgisch koninklijk besluit:
- gratis publicatie en uitwisseling, bovenop de publicaties, van de gegevens die verzameld of geproduceerd worden tijdens onderzoeksactiviteiten en gebruikt als bewijselementen in het onderzoeksproces (variabele modaliteiten naargelang het al dan niet vertrouwelijke karakter van de gegevens, van de toepassing van de GDPR, …)
- aanmoediging van de verspreiding van gegevens met grote toegevoegde waarde, dit wil zeggen waarvan het hergebruik belangrijke voordelen biedt voor de samenleving, het milieu en de economie, met name vanwege hun geschiktheid voor het ontwikkelen van diensten met toegevoegde waarde en van toepassingen, en voor het scheppen van nieuwe, hoogwaardige en fatsoenlijke banen, en vanwege het aantal potentiële begunstigden van op basis van die datasets ontwikkelde diensten of toepassingen met toegevoegde waarde” (PSI 2019). Dit betreft onder andere de volgende toepassingsdomeinen: meteorologie, aardobservatie, milieu,…

- Publicatie van de broncode van de toepassingen van de overheidsdiensten (met uitzonderingen waarmee deze publicatie kan verboden worden, onder andere in het geval van hackrisico, voor algoritmes bedoeld voor de strijd tegen sociale of fiscale fraude, in geval van schending van intellectueel recht, GDPR en ook wat betreft uitwisselingen tussen politieke instellingen en de overheden, enz.)
Data Governance Act (30 mei 2022, van toepassing 9/2023)
In 2014 hebben we voorgesteld de term ‘closed data’ te gebruiken om open data aan te duiden die privé verwerkt worden binnen een gesloten informatiesysteem (bijvoorbeeld in de strijd tegen sociale fraude). In het kader van de DGA zouden we deze benaming kunnen toepassen op de gegevens uit de overheidssector die niet ter beschikking gesteld kunnen worden als open gegevens maar die hergebruikt zouden kunnen worden in een wettelijk kader en onder specifieke voorwaarden. We denken bijvoorbeeld aan medische gegevens waarvan hergebruik kan dienen voor onderzoek, wat in België geleid heeft tot de oprichting van het Health Data Agency (HDA).
Het doel van deze reglementering is om het onderzoek te bevorderen terwijl deze gegevens in een beveiligde context worden verspreid in lijn met het werk van Kristof Verslype over pseudonymisering. Om dit doel te bereiken, moet elke EU-lidstaat één informatiepunt opzetten om informatie over gegevens die door overheidsinstanties worden beheerd, door te geven aan een gemeenschappelijk Europees register (ERPD) en zo het hergebruik ervan te vergemakkelijken.
Op basis daarvan is het ook mogelijk om “data spaces” op te richten. Dit zijn omgevingen waarbinnen gegevens beveiligd en uitgewisseld worden naargelang de behoeften.
Data Act (13 december 2023, van toepassing 9/2025)
Het doel hiervan is om gegevens te delen, voornamelijk uit de privésector, waarbij toegangs- en gebruiksrechten uitgeklaard worden alsook de uitwisselingen die kunnen plaatsvinden tussen ondernemingen en naar de eindgebruiker. In het geval van een smartwatch bijvoorbeeld zal de gebruiker toegang kunnen vragen tot de gegevens die bijgehouden worden door de ondernemingen die het product verschaffen en deze met derden kunnen delen (bijvoorbeeld voor een herstelling).
Interoperable Europe Act (13 mars 2024, d’application 01/2025)
Deze verordening betreft “de grensoverschrijdende interoperabiliteit van netwerk- en informatiesystemen die worden gebruikt voor het verlenen of beheren van overheidsdiensten in de Unie moet worden versterkt om overheidsdiensten in de Unie in staat te stellen samen te werken en overheidsdiensten over de grenzen heen te laten functioneren”. Dat betekent onder andere een verplichte evaluatie van de interoperabiliteit van de nieuwe diensten vanaf hun ontwerp (“interoperable-by-design public services“), zowel op functioneel als semantisch vlak. Dit impliceert ook de verplichting om broncode te publiceren van de overheidsinstellingen (behalve uitzonderingen, zie hoger). Er blijft een openstaand probleem opdat deze verordening operationele resultaten kan bieden voor het leven van de Europese burgers: de harmonisering van de wetgeving tussen de EU-landen.
De uitdagingen: kwaliteit evalueren en ROI van de ‘Open data’
De kwaliteit van de ‘Open data’
Onderstaand schema toont duidelijk de uitdagingen van ‘Open data’ die in 2014 minder openlijk gespecificeerd werden door de EU-overheden. Verschillende domeinen moeten interageren in verschillende talen en in een internationale context. Het geheel evolueert op een verschillend tempo. Dit kan leiden tot kwaliteitsproblemen van de gegevens (fitness for use) (3) naargelang de min of meer georganiseerde omkadering van de verspreiding van open data. Bijvoorbeeld op het Belgische federaal platform voor open data dat deel uitmaakt van BOSA zijn de leveranciers van open data verantwoordelijk voor de kwaliteit, de beschrijving en de regelmatige updates van deze data. Natuurlijk is feedback vragen aan de gebruikers over de kwaliteit van de gebruikte open data een good practice die vaak voorgesteld wordt (dat is bijvoorbeeld het geval van de KBO in België wat betreft hun open data). Op Europees niveau zijn de leveranciers van gegevens ook verantwoordelijk en ondanks de publicatie van richtlijnen blijft de kwaliteit van het Europees portaal voor open data zeer variabel.
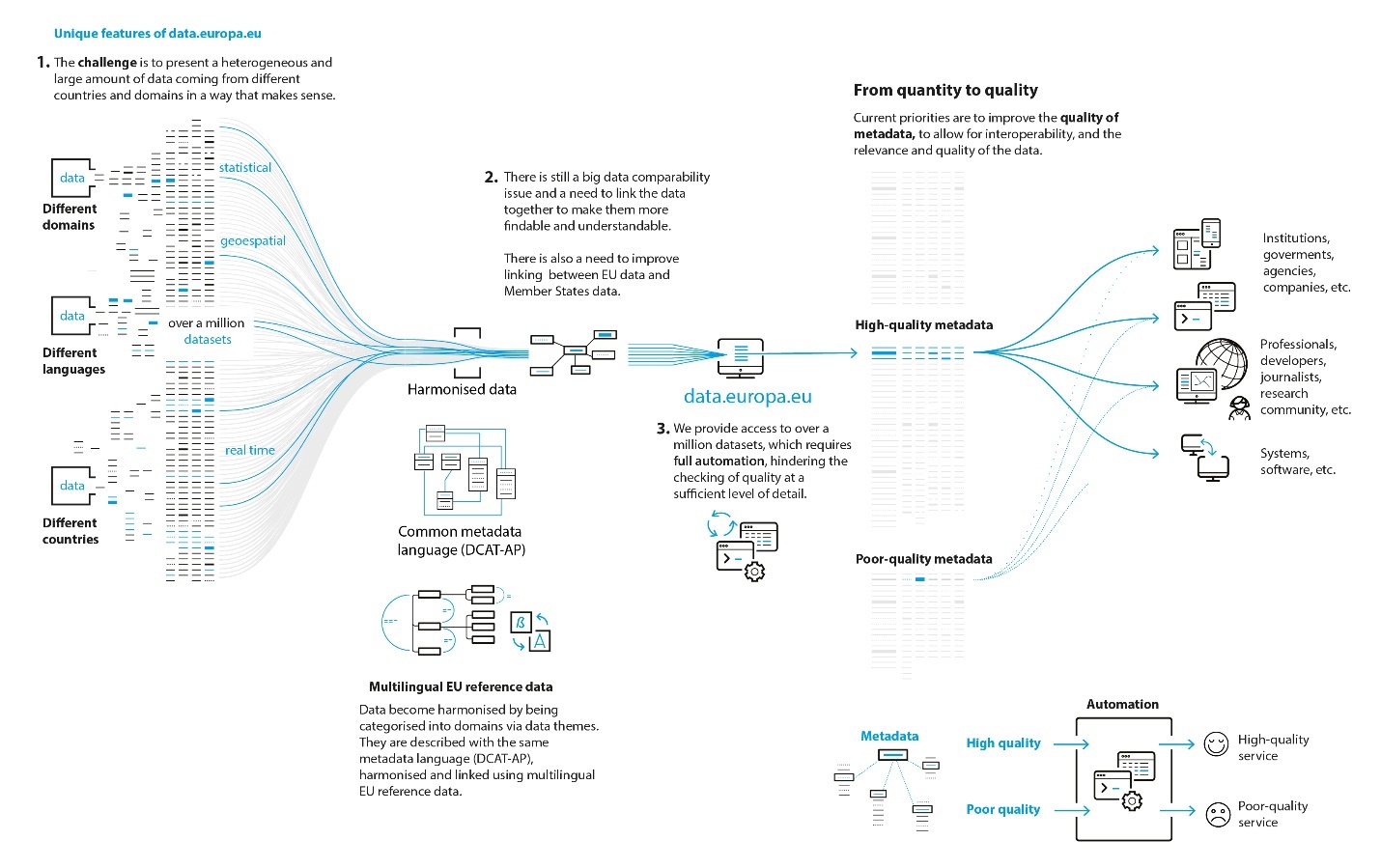
Bron : https://dataeuropa.gitlab.io/data-provider-manual/
Als het gaat over gegevenskwaliteit merken we op dat er verschillende barometers bestaan die onderling landen vergelijken op basis van kwaliteitscriteria: bijvoorbeeld een barometer in 2018 op internationaal niveau (W3C), of de UE Open Data Maturity Assessment, een jaarverslag dat, sinds 2015 en sinds de invoering van het Europees portaal voor open data, een maturiteitsgraad voor elk land toekent op basis van een verzameling ‘vragen-antwoorden’ waaraan een min of meer willekeurige score wordt verbonden. Er wordt eveneens een ‘fact sheet’ uitgewerkt per land (bijvoorbeeld in 2023 voor België).
De ROI van ‘Open Data’
Een andere openstaande vraag betreft de ROI die soms zeer hoog ligt en zonder uitleg toegewezen wordt aan de Open Data. Hoewel we de kosten die te maken hebben met de verspreiding van kwaliteitsvolle open data wel kunnen inbeelden, vragen we ons af wat de voordelen zijn voor de verspreiders, zoals de federale overheid? Het onderzoek van F. W. Donker van de universiteit van Delft stelt een model voor op basis van concrete maar wel uiteenlopende heterogene waarnemingen.
Dit model stelt een lus met positieve retroactie voor (‘positieve spiraal’); als de overheid gratis en kwaliteitsvolle open data verspreidt, zullen deze gebruikt worden door onderzoekers of ondernemingen die op hun beurt nieuwe activiteiten gaan creëren, die op hun beurt op termijn een bron van belastingen en financiële inkomsten betekenen voor de Staat. Andere voorbeelden worden voorgesteld in een andere context. Op die manier “Costs can be saved when re-using open data instead of paying for the data that is commercially published. In the Netherlands for example, users were charged approximately €63-€68 million for using the datasets from PSI providers such as the Dutch Chamber of Commerce, the Cadastre, the CBS (the Dutch national statistics agency) in 2009-2010. As these datasets are now freely available, users can save themselves these costs. Moreover, more people and organisations can start to use this data as the financial barrier is now removed.“. De voordelen zijn dus duidelijk voor de gebruikers als de voorheen betalende open data nu gratis worden. De voorwaarde is dat de overheid over de middelen beschikt om kwaliteitsvolle data te verschaffen die up-to-date en gedocumenteerd zijn. Dat is helemaal niet evident aangezien er geen zekerheid is dat de nieuwe gegenereerde inkomsten toegekend zullen worden aan de dienst die de Open Data verspreidt.
We kunnen vaststellen uit deze verschillende evoluties dat de bedenkingen, praktijken en de wetgeving wat betreft open data steeds matuurder worden. Open data is een topic op zich dat serieus opgevolgd moet worden in het kader van het eGovernment en dat van de burgermaatschappij of privésector.
Het team Data Quality bij Smals staat ter beschikking om u te helpen bij het evalueren en verbeteren van de kwaliteit van de gegevens: de lezer kan meer informatie vinden over het competentiecentrum op de website van Smals (FR en NL).
Referenties
(1) Isabelle Boydens, Open Data et eGovernment. Research Note, Brussel, Smals, nr. 33, april 2014, 23 pp. (link naar het verslag en de samenvatting).
(2) Irène Bouhadana, William Gilles, Open Data. Toegangsrecht en hergebruik van openbare informatie in de datamaatschappij. Parijs, LexisNexis, 08/11/2023.
(3) Isabelle Boydens, Gani Hamiti en Rudy Van Eeckhout, A service at the heart of database quality. Presentation of an ATMS prototype. In Le Courrier des statistiques, Parijs, INSEE, 2023, nr. 6, 11 p. (gepubliceerd op 2/10/2023). Link naar het artikel.
Isabelle Boydens(*) et Isabelle Corbesier(**)
(*) Data Quality Expert, Research Team
(**) Data Quality Analyst, Databases Team
Dit bericht is een gezamenlijke bijdrage van Isabelle Boydens, Data Quality Expert bij Smals Research en van Isabelle Corbesier, Data Quality Analysts bij Smals, Databases Team. Dit artikel is geschreven onder hun eigen naam en weerspiegelt op geen enkele wijze de standpunten van Smals.
Leave a Reply