En 2014, nous publiions une research note sur les “Open Data” suite à la parution de la directive européenne PSI (Public Service Information) 2013 applicable en 2015 (1).
Depuis lors, d’autres législations européennes sont parues ou en cours de parution. Ces nouvelles lois n’invalident rien de ce qui était d’application en 2014 (mis à part certains url de la note de recherche de 2014 qui ne sont plus à jour) mais en élargissent considérablement le champ d’application (2) que nous présentons dans cet article de blog.
Nous ne revenons pas ici sur la définition des “open data”, sur leur caractère possiblement payant (coût marginal de la mise à disposition d’un service web, par exemple dans le cas de la KBO et des bases de données d’entreprise en général) ou sur la question des licences et renvoyons le lecteur pour cela à la research note de 2014.
Ces nouvelles règlementations se sont déployées dans un contexte où de nombreuses études de cas résultant de la diffusion d’open data ont donné lieu à des exploitations positives, par exemple fin 2023, la décision de la publication ouverte des données météorologiques en France en vue de stimuler la recherche et les échanges entre chercheurs “L’établissement mettra en place de nouvelles possibilités techniques d’accès par API à ses données d’observation, climatologiques et radar, sans aucun frais” (voir lien supra). Ainsi, dès 2014, nous avions montré combien la mise à disposition de données météorologiques et géographiques dynamiques aux USA, couplée à l’utilisation des réseaux sociaux, permettait en cas d’ouragan d’identifier les zones de danger et aux personnes en mesure de proposer leur aide (hébergement, etc) d’entrer en contact avec les personnes démunies. Le schéma suivant illustre le circuit idéal des “open data” depuis la collecte jusqu’à l’exploitation des données.
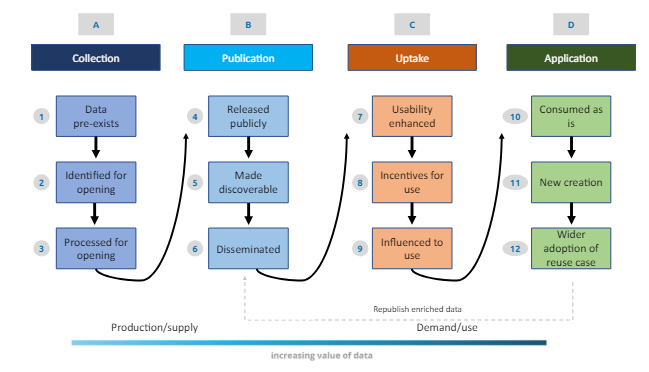
Source : Open data value chain, adapted from Open Data Watch in Indicators for an Open Data Impact Assessment (UE)
Dans la suite de cet article de blog, nous envisageons :
- 4 législations (une directive et 3 actes)
- le challenge de la qualité des données et du ROI des open data
Directive PSI 2019 (d’application en 2021, transposée dans la loi belge en décembre 2023)
Cette directive implique notamment l’intégration des éléments nouveaux suivants dans l’arrêté royal belge :
- publication gratuite et échange, en plus des publications, des données recueillies ou produites au cours d’activités de recherche et utilisées comme éléments probants dans le processus de recherche (modalités variables en fonction du caractère confidentiel ou pas des données, de l’application du GDPR, …)
- encouragement de la diffusion de données à forte valeur ajoutée, c’est-à-dire “dont la réutilisation est associée à d’importantes retombées positives au niveau de la société, de l’environnement et de l’économie, en particulier parce qu’ils se prêtent à la création de services possédant une valeur ajoutée, d’applications et de nouveaux emplois décents et de grande qualité, ainsi qu’en raison du nombre de bénéficiaires potentiels des services et applications à valeur ajoutée fondés sur ces ensembles de données” (PSI 2019). Cela concerne notamment les domaines d’application suivants : météorologie, geospatial, environnement, …

Source : https://data.europa.eu/en/publications/datastories/high-value-datasets-overview-through-visualisation
- Publication du code source des applications des administrations publiques (avec des exceptions qui permettent d’interdire cette publication, notamment en cas de risque de hacking, pour les algorithmes destinés à la lutte contre la fraude sociale ou fiscale, en cas de violation du droit intellectuel, du GDPR ou encore, en ce qui concerne les échanges entre les instances politiques et les administrations,…)
Data Governance Act (30 mai 2022, d’application 09/2023)
En 2014, nous avions proposé d’utiliser le terme “closed data” pour désigner des open data qui feraient l’objet d’un traitement privé au sein d’un système d’information fermé (par exemple, lutte contre la fraude sociale). Dans le cadre du DGA, nous pourrions appliquer cette dénomination aux données du secteur public qui ne peuvent pas être mises à disposition en tant que données ouvertes mais qui pourraient être réutilisées dans un cadre législatif et sous des conditions spécifiques. On pense par exemple aux données médicales dont la réutilisation permettrait de favoriser la recherche, ce qui a donné lieu en Belgique à la création de la Health Data Agency (HDA).
Le but de cette règlementation est de favoriser la recherche tout en diffusant ces données dans un contexte sécurisé, dans la ligne des travaux de Kristof Verslype sur la Pseudonymisation. Pour atteindre cet objectif, chaque État membre de l’UE est tenu de mettre en place un point d’information unique censé relayer les informations concernant les données gérées par les autorités publiques vers un registre européen commun (ERPD) et ainsi faciliter leur réutilisation.
Sur cette base, il est également possible de construire des “data spaces“, environnements au sein desquels les données sont sécurisées et échangées en fonction des besoins.
Data Act (13 décembre 2023, d’application 09/2025)
L’objectif est ici de faciliter le partage des données, notamment du secteur privé, en clarifiant les droits d’accès et d’utilisation de celles-ci ainsi que les échanges qui peuvent avoir lieu entre entreprises et vers l’utilisateur final. Dans le cas d’une montre connectée par exemple, l’utilisateur pourra demander l’accès aux données détenues par les entreprises qui fournissent le produit, et pourra partager celles-ci avec des tiers (en vue d’une réparation par exemple).
Interoperable Europe Act (13 mars 2024, d’application 01/2025)
Cet acte concerne quant à lui “l’interopérabilité transfrontière des réseaux et des systèmes d’information qui sont utilisés pour fournir ou gérer des services publics dans l’Union, afin de permettre aux administrations publiques de l’Union de coopérer et de faire fonctionner les services publics par-delà les frontières”. Cela passe notamment par une évaluation obligatoire de l’interopérabilité des nouveaux services dès leur conception (“interoperable-by-design public services“), que ce soit au niveau fonctionnel ou sémantique. Cela implique également l’obligation de publier le code source des administrations publiques (sauf exceptions, voir plus haut). Une question ouverte subsiste afin que cet acte puisse donner des résultats opérationnels pour la vie des citoyens européens : l’harmonisation de la législation entre pays de l’UE.
Les challenges : évaluer la qualité et le ROI des “open data”
La qualité des “open data”
Le schéma suivant illustre bien les challenges soulevés par les “open data” qui avaient été moins ouvertement spécifiés par les autorités de l’UE en 2014. Il s’agit de faire interagir différents domaines, dans différentes langues et dans un contexte international, le tout évoluant à un rythme hétérogène. Cela peut mener à des problèmes de qualité de données (fitness for use) (3) en fonction de l’encadrement plus ou moins organisé de la diffusion des open data. Par exemple, sur la plateforme fédérale belge des open data, dépendant de BOSA, ce sont les fournisseurs des open data qui ont la responsabilité de la qualité de celles-ci, de leur description et de leur mise-à-jour régulière. Naturellement, demander aux utilisateurs un feed back concernant la qualité des open data utilisées constitue toujours une bonne pratique souvent proposée (c’est le cas de la KBO en Belgique, par exemple, s’agissant de leurs open data). Au niveau européen également, ce sont les fournisseurs de données qui sont responsables, et malgré la publication de guidelines, la qualité du portail européen des open data reste très variable.
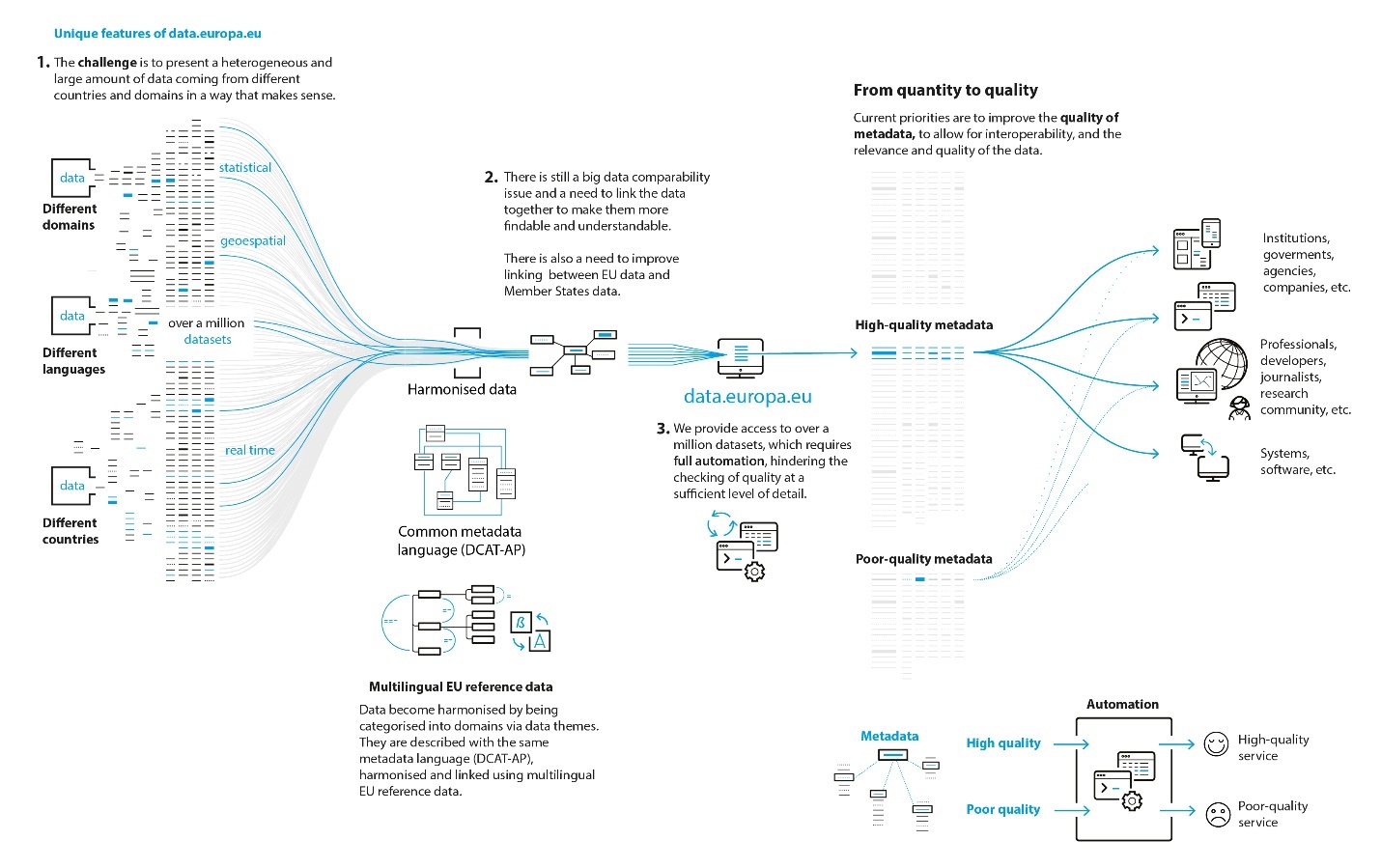
S’agissant de la qualité des données, notons qu’il existe différents baromètres comparant entre eux des pays sur la base de critères de qualité; par exemple, un baromètre en 2018 au niveau international (W3C), ou l’UE Open Data Maturity Assessment, rapport annuel qui, depuis 2015 et la mise en place du Portail européen des données, attribue un niveau de maturité à chaque pays sur la base d’un ensemble de “questions-réponses” auxquelles sont associés un score de façon plus ou moins arbitraire. Une “fact sheet” est également élaborée par pays (par exemple en 2023, pour la Belgique).
Le ROI des “Open Data”
Une autre question ouverte concerne le ROI parfois très élevé attribué aux Open Data sans explication aucune de celui-ci. Si l’on imagine bien les coûts liés à la diffusion d’open data de qualité, quels sont les bénéfices pour les diffuseurs, tels que l’administration fédérale ? Les recherches de F. W. Donker de l’Université de Delft proposent un modèle sur la base d’observations concrètes mais forcément hétérogènes.
Ce modèle propose une boucle avec rétroaction positive (“cercle vertueux”) ; si l’administration diffuse des open data gratuites et de qualité, celles-ci seront utilisées par des chercheurs ou des entreprises qui, à leur tour, vont créer de nouvelles activités, lesquelles constitueront, à terme, des sources de taxes et rentrées financières pour l’État. D’autres exemples sont proposés, dans un autre contexte. Ainsi, “Costs can be saved when re-using open data instead of paying for the data that is commercially published. In the Netherlands for example, users were charged approximately €63-€68 million for using the datasets from PSI providers such as the Dutch Chamber of Commerce, the Cadastre, the CBS (the Dutch national statistics agency) in 2009-2010. As these datasets are now freely available, users can save themselves these costs. Moreover, more people and organisations can start to use this data as the financial barrier is now removed.“. Les bénéfices sont donc évidents pour les utilisateurs si les open data autrefois payantes deviennent gratuites, à condition que l’administration ait les moyens de fournir gratuitement des données de bonne qualité, bien mises à jour et documentées, ce qui est loin d’être évident puisque rien ne garantit que les nouveaux revenus générés seront attribués au service en charge de la diffusion des Open Data.
Nous pouvons conclure de ces différentes évolutions que la réflexion, les pratiques et la législation autour des open data sont devenues de plus en plus matures. Il s’agit d’un topic à part entière à suivre sérieusement dans le cadre de l’egovernement ainsi que dans celui de la société civile ou privée.
La team Data Quality chez Smals est disponible pour toute aide en vue d’évaluer et d’améliorer la qualité des données : le lecteur trouvera plus d’information sur son centre de compétence sur le web site de Smals (FR et NL).
Références
(1) Isabelle Boydens., Open Data et eGovernment. Research Note, Bruxelles, Smals, n° 33, avril 2014, 23 pp. (lien vers le rapport et l’abstract).
(2) Irène Bouhadana, William Gilles, L’Open Data. Droit d’accès et de réutilisation des informations publiques dans la société des données. Paris, LexisNexis, 08/11/2023.
(3) Isabelle Boydens., Gani Hamiti et Rudy Van Eeckhout., A service at the heart of database quality. Presentation of an ATMS prototype. In Le Courrier des statistiques, Paris, INSEE, 2023, n°6, 11 p. (publié le 2/10/2023). Lien vers l’article.
Isabelle Boydens(*) et Isabelle Corbesier(**)
(*) Data Quality Expert, Research Team
(**) Data Quality Analyst, Databases Team
Ce post est une contribution collective d’Isabelle Boydens, Data Quality Expert chez Smals Research et d’Isabelle Corbesier, Data Quality Analysts chez Smals, Databases Team. Cet article est écrit en leur nom propre et n’impacte en rien le point de vue de Smals.
Leave a Reply