Ces dernières années, les bases de données orientées graphes (ou Graph DB, présentées dans nos blogs précédents [1, 2]), et plus généralement les bases de données NoSQL, ont énormément gagné en popularité et en visibilité. Pour preuve, Neo4j, le leader actuel du marché des Graph Databases, apparaît depuis 2014 dans le “Magic Quadrant for Operational Database Management Systems (DBMS)“, et n’en est plus sorti depuis, et depuis 2018 dans le “Magic Quadrant for Data Management Solutions for Analytics“. Le site “DB engine” positionne Neo4J à la 22ème position de son classement de popularité de l’ensemble de 330 solutions de gestion de bases de données (tous modèles confondus).
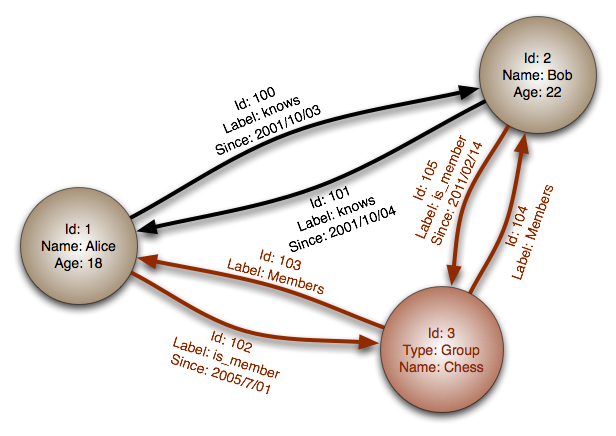
Les bases de données (orientées) graphes sont très souples, et d’un point de vue modélisation, sont capables de modéliser facilement tout ce qui peut l’être avec une RDBMS (bases de données relationnelles, telles que Oracle, Postgresql ou MySQL). La réciproque n’est pas forcément vraie, en tout cas pour l’aspect “facilement”. La tentation peut dès lors être grande, pour des développeurs qui aiment la nouveauté, de vouloir tout faire dans un modèle graphe. C’est loin d’être toujours la meilleure solution et il conviendra, avant de se lancer dans un changement de paradigme, de se poser les bonnes questions. Nous allons au travers des 7 sections suivantes, essayer de contribuer modestement à cette réflexion.
Notons tout d’abord que, comme mentionné dans notre article précédent, la question n’est souvent pas de choisir un RDBMS ou une Graph DB, mais plutôt de voir comment ces deux modèles peuvent se compléter, et quel sera le champ d’application de ceux-ci.
Il s’agit ici de quelques pistes de réflexion ; les différents aspects ici ne sont ni exclusifs, ni exhaustifs, et l’ordre n’est pas pertinent.
1. Relations au centre de tout
La condition de base pour pouvoir utiliser une Graph DB, c’est que les données puissent être séparées clairement entre nœuds (ou entités) et relations (ou lien) entre ceux-ci. Chaque donnée sera soit un attribut d’un nœud, soit un attribut d’une relation (soit un type de nœud ou de relation). Mais ceci est également vrai pour un modèle relationnel, puisqu’une des premières étapes de l’analyse classique consiste à décrire le schéma “entité-relation”.
Dans un modèle graphe, on s’attendra à ce que les relations aient un rôle au moins aussi important que les entités, si pas plus. Et qu’elles aient un sens fondamental, par rapport au business, et pas uniquement parce que la relation est nécessaire d’un point de vue technique, pour permettre l’implémentation du modèle.
Prenons pour exemple un cas où l’on doit implémenter un annuaire de personnes, où chaque personne peut avoir plusieurs numéros de téléphone (et supposons qu’un même numéro ne peut pas être attribué à plusieurs personnes). Dans un modèle relationnel, on parlerait d’une relation “one-to-many”. Il serait assez artificiel de considérer que les personnes et les numéros de téléphone sont des entités, entre lesquelles on établit une relation. Cette relation n’aurait pas réellement de sens “business”. Le focus ici n’est pas sur la relation, mais plutôt sur l’information, multi-valuée dans ce cas-ci. Un modèle RDBMS à deux tables (People et PhoneNumbers) fera très bien l’affaire.
Par contre, un service de police ou de renseignement qui veut suivre des téléphones pourrait clairement considérer les téléphones et les personnes comme des entités, car les relations auront ici un rôle fondamental : quel téléphone appelle quel téléphone (relation), quand et combien de temps (attribut de la relation), qui possède quel téléphone (relation) à quel moment (attribut de la relation).
2. Beaucoup de relations “many-to-many”
Une particularité d’une relation “many-to-many” dans un modèle RDBMS est qu’elle implique une complexité d’implémentation importante.
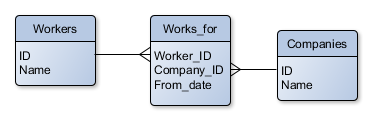
Reprenons l’exemple de notre blog précédent, illustré ci-contre, où l’on modélisait la relation entre des travailleurs et leurs employeurs. Une implémentation dans un modèle RDBMS requiert deux tables représentant les entités (“Workers” et “Companies”), une table représentant la relation (“Works_for”), et la gestion fastidieuse d’une série de clés primaires et étrangères à utiliser dans chaque requête.
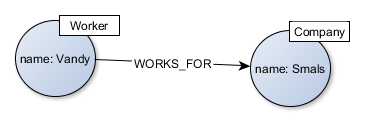
Une relation dans une Graph DB est représentée beaucoup plus naturellement, sans gestion de clés “artificielles” ou de tables techniques intermédiaires.
Au plus le nombre de relations “many-to-many” est important dans le modèle de données, au plus grand est le bénéfice de l’utilisation d’une Graph DB.
3. Beaucoup de “joins” entre des grandes tables
Outre le fait que l’utilisation des “join tables” ajoute une grande complexité, tant en lisibilité du modèle qu’en lisibilité des requêtes, chaque “JOIN” dans une requête SQL nécessite de parcourir une des deux tables de la jointure. Ce parcours, dans le meilleur des cas (si la clé de jointure est indexée), nécessitera un temps logarithmique par rapport à la taille de la table.
Ce n’est pas un problème si la table parcourue est petite. Il peut par exemple s’agir d’une table de traduction, qui convertit un code en un label (code pays > pays, code département > nom de département…). C’est nettement plus problématique si l’on veut connaître tous les produits achetés par un client particulier : il faudra sans doute d’abord parcourir toutes les commandes pour trouver celles du client, puis tous les produits, sans compter la “join table” que l’on aura entre les commandes et les clients. Cette opération, pourtant toute simple du point de vue business, nécessite une requête SQL aussi complexe que la suivante :
SELECT p.name
FROM product AS p
JOIN prod_2_com AS pc ON pc.prod_id = p.id
JOIN command AS c ON pc.com_id = c.id
JOIN user AS u ON c.user_id = u.id
WHERE u.name = "Smith"
Dans un modèle Graph DB, on aura au niveau du nœud “Client”, directement accès à la liste des commandes, qui, elles-mêmes, donneront un accès à la liste des produits concernés. Le temps de parcours dépendra donc uniquement du nombre de commandes du client concerné (et pas de l’ensemble global des commandes), et, pour chaque commande, du nombre de produits associés. La requête Cypher, langage de Neo4J, réalise la même opération que la requête SQL ci-dessus, avec une complexité largement inférieure, et une performance incomparablement meilleure, à tout le moins pour des grosses bases de données :
MATCH (u:USER {name:"Smith"})--(:COMMAND)--(p:PRODUCT)
RETURN p.name
Si, dans la représentation du modèle pour une RDBMS, on se rend compte qu’il y a un grand nombre de “JOIN” entre des grandes tables, il sera pertinent d’étudier la possibilité d’une Graph DB.
4. Recherches locales
L’exemple donné dans la section précédente illustre très bien aussi le point suivant. Ce qui nous a intéressé, c’était, partant d’une entité clairement identifiée (le client “Smith” comme “starting point”), d’explorer son environnement immédiat (ses commandes, puis ses produits). C’est une situation où les Graph DB excellent.
Dans une situation qui nécessite de parcourir l’intégralité de certains attributs pour en agréger un résultat (calculer le montant moyen d’une commande, ou les clients les plus fidèles ayant dépensé le plus d’argent), une Graph DB a par contre très peu de chances de concurrencer une DB relationnelle.
5. Recherches de “patterns”
La recherche de “patterns” ne part typiquement pas d’un point connu, mais recherche toutes les occurrences d’une forme particulière de séquences de relations.
Continuons notre exemple ci-dessus, et supposons que l’entreprise vende des produits, mais également des parties de ceux-ci (des rasoirs et des lames de rasoir, des machines et des pièces de rechange…), et qu’une relation “PART_OF” soit présente dans les données. Il sera, avec une Graph DB comme Neo4J, facile de recherche l’ensemble des clients “prudents”, qui ont acheté un appareil ainsi que ses pièces de rechanges, dans la même commande ou non :
MATCH
(u:USER)--(:COMMAND)--(p1:PRODUCT),
(u)--(:COMMAND)--(p2:PRODUCT),
(p1)-[:PART_OF])-(p2)
RETURN u.name, p1.name, p2.name
La même requête en SQL aurait été d’une complexité sans nom, tant en terme d’écriture qu’en terme de vélocité d’exécution.
6. Besoin de flexibilité
Une base de données comme Neo4j apporte beaucoup de flexibilité à deux niveaux :
- Elle est “schema-less”, ce qui signifie que :
- Les attributs ne sont pas figés. C’est à la création d’un nœud qu’on détermine ses attributs, il n’est pas nécessaire que ceux-ci aient été figés à l’avance, ni qu’ils soient les mêmes que dans les autres nœuds du même type.
- Le type de nœud ne l’est pas non plus. S’il existe un nœud “Worker” à la création de l’application, on peut décider par la suite de rajouter un label “Manager”, simplement en rajoutant ce label sur des nœuds existant ou en créant de nouveaux nœuds avec ce label.
- Les extrémités d’une relation ne sont pas figées. Une relation “DEPENDS_ON” peut à la fois relier deux nœuds “People” ou deux nœuds “Package”.
Cette flexibilité peut être un grand atout, car elle permet de faire évoluer le modèle de données, sans avoir de conséquence sur ce qui tourne déjà. Mais elle peut être aussi vue comme une faiblesse : il sera facile de créer accidentellement un nœud avec un attribut “name”, et un autre avec un attribut “Name”, qui risque de passer alors sous le radar de requêtes basées sur “name”. Ou de créer une relation entre deux nœuds pour lesquels cette relation n’a pas de sens (PART_OF entre deux clients, par exemple). La responsabilité de la cohérence se reposera alors sur la couche applicative.
Notons que les Graph DB ne sont pas les seules à offrir beaucoup de flexibilité ; c’est également en général le cas de bases de données “Key-value” (Redis…), ou des Document stores (MongoDB…)
7. Requêtes orientées “chemins”
Supposons qu’un employé A d’une entreprise doivent transmettre une information stratégique à un employé B, et qu’il doive du coup absolument passer par la ligne hiérarchique : il faut donc identifier “N+x” de A qui serait le “N+y” de B, où “x” et “y” ne sont pas connus. Ou imaginons que l’on gère les dépendances entre l’ensemble des modules produits par une entreprise de développement, et que l’on ait besoin d’identifier tous les modules qui seront impactés, directement ou indirectement, par la mise à jour prévue d’un module. Ou encore une chaîne de production, qui doit connaître le “chemin critique” de production d’un objet, ou encore l’ensemble des produits dont la production serait mise à l’arrêt par l’entretien d’une machine de la chaîne.
Ce type de situation nécessite l’identification d’un chemin, c’est-à-dire une succession de relations, dont on ne connaît souvent pas à l’avance le nombre. En SQL, il faudrait donc une requête pour laquelle le nombre de “JOIN” n’est pas fixé. À notre connaissance, il n’existe pas de solution standard à ce problème (le “CONNECT BY” de Oracle et le “RECURSIVE” de Postgre ne s’utilisent pas du tout de la même façon).
Dans Neo4j, on pourra très facilement identifier le plus court chemin entre deux nœuds, ou l’ensemble des plus courts chemins, voire même l’ensemble des chemins possibles, en faisant alors attention au risque d’explosions combinatoire. On pourra aussi identifier l’ensemble des chemins entre deux nœuds, ne comportant que des relations d’un type donné, comprenant entre 5 et 10 sauts.
Conclusions
Cette liste n’est bien sûr pas exhaustive, et n’est pas à prendre au pied de la lettre. Les différents éléments seront parfois contradictoires : on peut avoir un modèle avec beaucoup de relations many-to-many, sur lesquelles il sera nécessaire de faire de nombreuses opérations d’agrégation. Il faudra alors mettre en balance différents arguments ; Quelles sont les opérations qui devront être réactives, liées à une interface utilisateur, et quelles sont celles qui se feront “en batch” la nuit, sans nécessité d’interactivité ? Est-il préférable d’avoir une application très performante, ou plutôt basée sur une technologie bien maîtrisée par l’entreprise ? Chacun aura sa propre réponse.
On pourrait encore identifier beaucoup d’autres situations ou une Graph DB offre des avantages ; ou des situations où il ne faut surtout pas s’en servir. Les liens ci-dessous permettront au lecteur de continuer la réflexion.
Il est à notre sens clair que, bien que les Graph DB ne soient pas adaptées ou optimales dans toutes les situations, elles ont de solides avantages dans de nombreuses circonstances, y compris dans d’innombrables applications ou le choix d’une RDBMS a été fait, soit par ignorance d’alternatives, soit par peur face à un changement de paradigme.
Inspirations
- https://medium.com/neo4j/how-do-you-know-if-a-graph-database-solves-the-problem-a7da10393f5
- https://linkurio.us/blog/unlocking-value-connected-data/
- https://www.infoworld.com/article/3251829/nosql/why-you-should-use-a-graph-database.html
- http://radar.oreilly.com/2013/07/why-choose-a-graph-database.html
Leave a Reply