Isabelle Boydens(*) en Gani Hamiti(**)
(*) Data Quality Expert, Research Team
(**) Data Quality Analyst, Databases Team
![]() De kwaliteit van een gegeven is de geschiktheid ervan voor gebruik en voor de beoogde doelstellingen (‘fitness for use’) (Boydens, 1999, Boydens 2014). In dit artikel gaan we bekijken hoe een rigoureuze typologie van de anomalieën een kader biedt voor de verbetering van de kwaliteit van de gegevens, in verschillende domeinen, waaronder machine learning. Over ML zullen we in een later artikel aantonen hoe deze techniek de functionaliteiten van een ‘data quality tool’ kan verbeteren, bijvoorbeeld in de matchingoperaties, zoals aangekondigd in ons artikel van december 2021.
De kwaliteit van een gegeven is de geschiktheid ervan voor gebruik en voor de beoogde doelstellingen (‘fitness for use’) (Boydens, 1999, Boydens 2014). In dit artikel gaan we bekijken hoe een rigoureuze typologie van de anomalieën een kader biedt voor de verbetering van de kwaliteit van de gegevens, in verschillende domeinen, waaronder machine learning. Over ML zullen we in een later artikel aantonen hoe deze techniek de functionaliteiten van een ‘data quality tool’ kan verbeteren, bijvoorbeeld in de matchingoperaties, zoals aangekondigd in ons artikel van december 2021.
Een goed ontworpen operationele relationele database steunt op de ‘gesloten wereld’-hypothese: het definitiedomein specificeert de reeks waarden die zijn toegestaan binnen het databasemodel of schema (de integriteitsbeperkingen); ‘business rules’ zijn ook te vinden in de toepassingscode en dragen dus bij tot de definitie van de gegevens. In deze hypothese wordt een waarde die niet in het definitiedomein is opgenomen als foutief beschouwd en moet deze geweigerd worden uit de database.
Onder anomalie binnen een database verstaan we hier een formele fout (bv. een verplichte waarde die niet is vervolledigd), maar ook een veronderstelde fout die menselijke interpretatie vereist (bv. veronderstelde dubbels tussen sterk gelijkende records, opduiken van een nieuwe categorie van activiteit waarmee in de referentietabellen geen rekening is gehouden, enz.)
Hieraan moet worden toegevoegd dat een empirische databank in de loop der tijd evolueert met de interpretatie van de waarden die zij oplevert (Boydens, 1999, 2011, Bade, 2011). Bijgevolg is er nooit een één-op-één projectie tussen een database en de waarneembare werkelijkheid vertegenwoordigd. Totale kwaliteit bestaat niet. Dit maakt het des te complexer om een evaluatie- en verbeterstrategie op te zetten voor de gegevenskwaliteit, naargelang het gebruik ervan zoals machine learning (de Valeriola, 2020, 2021), op het gebied van justitie, gezichtsherkenning, ziektebehandeling of journalisme, … toegepast op zeer bijzondere doeleinden (Redman, 2018, Dierickx, 2022).

Laten we Redman en zijn eloquente voorbeelden aanhalen:
“Yet today, most data fails to meet basic “data are right” standards. Reasons range from data creators not understanding what is expected, to poorly calibrated measurement gear, to overly complex processes, to human error. To compensate, data scientists cleanse the data before training the predictive model. It is time-consuming, tedious work (taking up to 80% of data scientists’ time), and it’s the problem data scientists complain about most. Even with such efforts, cleaning neither detects nor corrects all the errors, and as yet, there is no way to understand the impact on the predictive model. What’s more, data does not always meet[s] “the right data” standards, as reports of bias in facial recognition and criminal justice attest.”
(…)
“Increasingly-complex problems demand not just more data, but more diverse, comprehensive data. And with this comes more quality problems. For example, handwritten notes and local acronyms have complicated IBM’s efforts to apply machine learning (e.g., Watson) to cancer treatment.”
Figuur 1. Preventieve en curatieve aanpakken
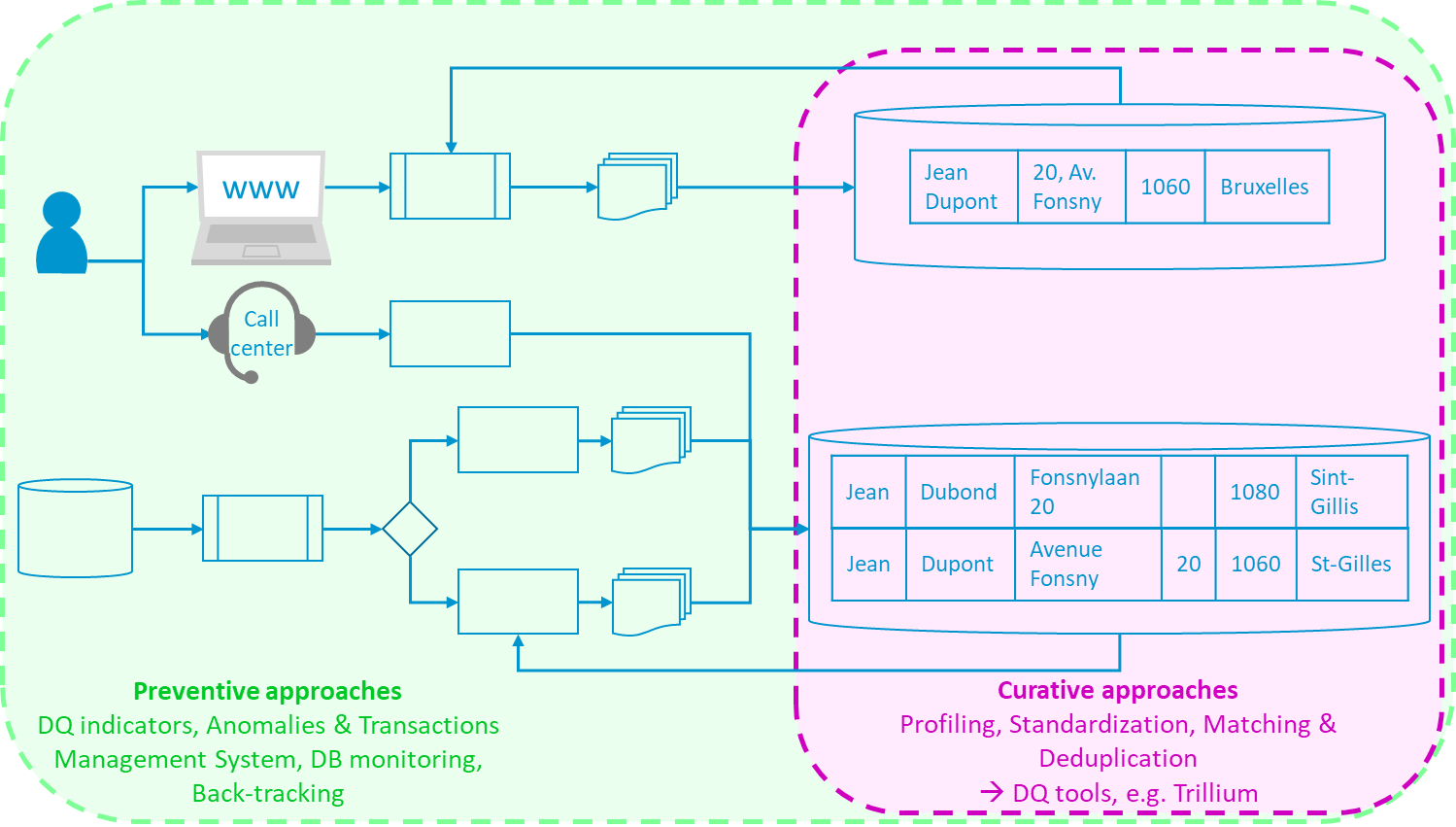
Naast het evidente belang voor gegevenskwaliteit is de studie naar anomalieën eveneens belangrijk omwille van het hoge percentage ervan dat de informaticasystemen structureel beïnvloedt: tot 10% van het gegevensvolume (Boydens, 2011, Van Der Vlist, 2011). Wanneer de inzet (menselijk, sociaal, financieel, juridisch, wetenschappelijk, medisch, enz.) het echter vereist, moeten deze anomalieën semiautomatisch of zelfs handmatig worden onderzocht, vaak langzaam en vervelend, zonder een ad-hocprogramma met preventieve en curatieve maatregelen, Figuur 1, (Boydens, 2014).
De typologie die we voorstellen kan nuttig zijn in alle disciplines die een beroep doen op Data: Database Management, Master Data Management, machine learning (Dierickx, 2022, Redman, 2018), … als een algemeen kader voor ‘Data Quality’-actie en helpt bij het identificeren van de meest geschikte verwerking.
Vanwaar komen de anomalieën, wat is de typologie ervan en hoe kunnen we ze van daar uit het beste beheren? Om op deze vragen te antwoorden, moeten we eerst terugkomen op het begrip ‘gegeven’ zoals we het kennen sinds 1999 en dat onlangs overgenomen werd in 2021 (Boydens I., Hamiti G. en Van Eeckhout R., 2021).
DETERMINISTISCHE GEGEVENS VS EMPIRISCHE GEGEVENS
In de wereld van de databases is een gegeven een triptiek (t, d, w) bestaande uit de volgende elementen:
- een titel (t), verwijzend naar een concept (een administratieve activiteitencategorie, bijvoorbeeld);
- een definitiedomein (d), bestaande uit formele beweringen die alle waarden in de database specificeren voor dit concept (een gecontroleerde lijst met alfabetische waarden van een maximale lengte l, bijvoorbeeld), eventueel aangevuld met business rules gevonden in de toepassingscode (zie hoger, hypothese van de gesloten wereld).
- En uiteindelijk een waarde (w) met een tijdstip t (de chemiesector, bijvoorbeeld).
We onderscheiden dan de deterministische gegevens van de empirische gegevens (Boydens, 1999, 2011).
- De eerste kenmerken zich door het feit dat we op eender welk moment over een theorie beschikken waarmee bepaald kan worden of een waarde w al dan niet correct is. Dit is het geval met een eenvoudige algebraïsche bewerking die betrekking heeft op een object dat zelf deterministisch is, zoals de som van waarden die betrekking hebben op een gegeven numeriek veld in een database op een tijdstip t. De algebraregels evolueren niet doorheen de tijd, we kunnen dus op elk moment weten of het resultaat van een dergelijke som al dan niet correct is. We hebben immers een stabiele referentie hiervoor.
- In het geval van empirische gegevens, onderworpen aan menselijke ervaring, evolueert de norm daarentegen in de tijd met de interpretatie van de waarden die erdoor kunnen worden waargenomen. Dit is bijvoorbeeld het geval op medisch gebied (waar de theorie evolueert met de waarnemingen van patiënten die aan een pathologie lijden, zoals blijkt uit het huidige onderzoek naar het coronavirus), maar ook op juridisch en administratief gebied, waar de interpretatie van juridische concepten verandert met de voortdurende evolutie van de behandelde werkelijkheid en met die van de jurisprudentie. Hoe kan de geldigheid van deze concepten worden beoordeeld bij gebrek aan een absolute referentie hiervoor?
TYPOLOGIE VAN DE ANOMALIEÊN EN MOGELIJKE BEHANDELINGEN
Vervolgens ontstaat een typologie van anomalieën, afhankelijk van hun mogelijke oorzaak en de manier waarop ze worden beschouwd:
- zekere formele fout: bijvoorbeeld een verplicht veld dat bij handmatige gegevensinvoer door een mens niet is ingevuld;
- veronderstelde formele fouten: bv. a) veronderstelde duplicaten als gevolg van redundante processen voor gegevensvastlegging stroomopwaarts, of b) inconsistentie met een referentietabel waarvan niet bekend is dat deze actueel is, bv. op het gebied van hernieuwbare energie (figuur 2);
- een fout die a priori niet formeel kan worden opgespoord: bijvoorbeeld het weglaten van een bijwerking.
Figuur 2. Beheer van de anomalieën, ATMS, Monitoring & Back tracking
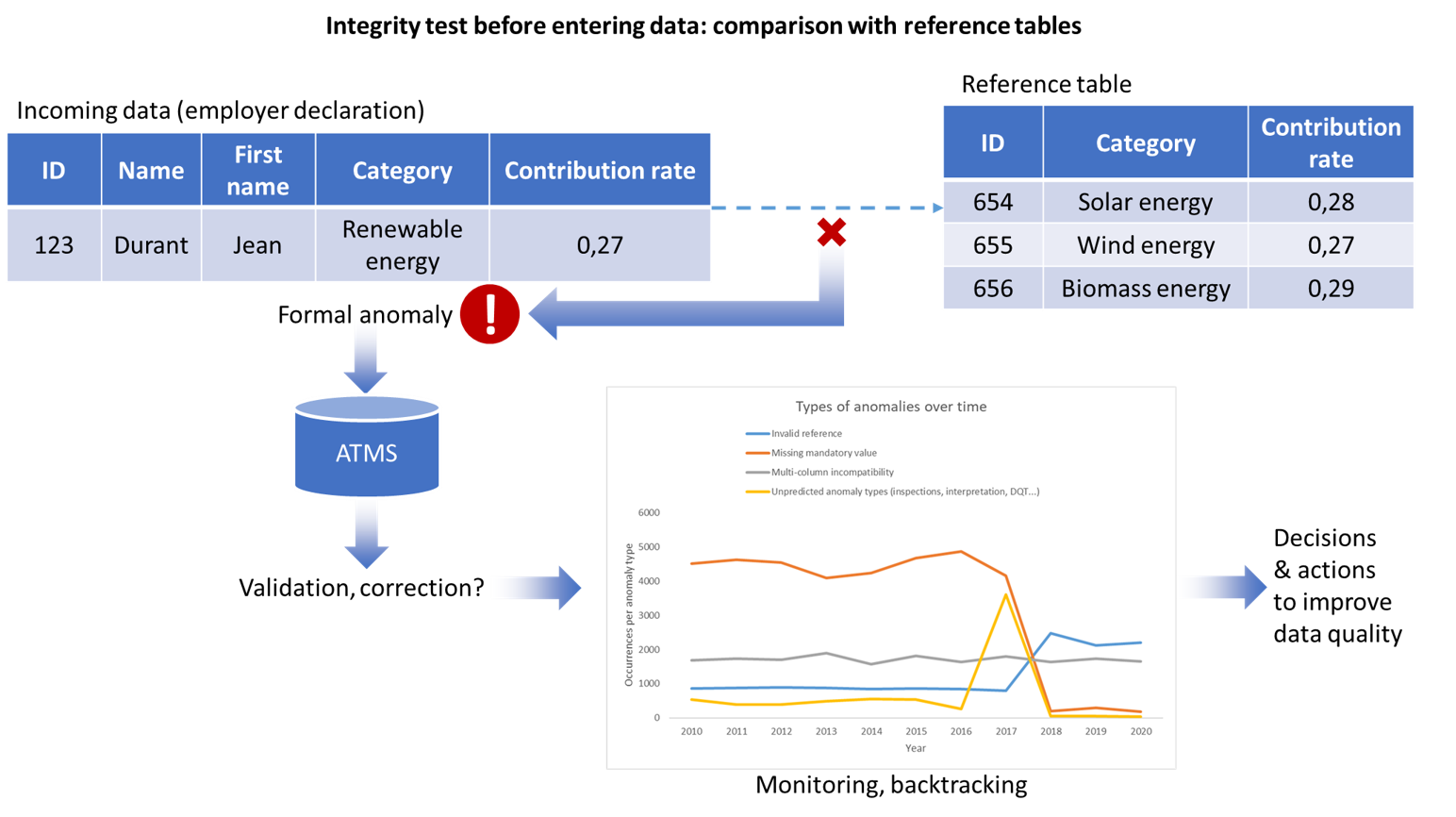
De laatste twee gevallen in bovenstaande typologie kunnen wijzen op anomalieën als gevolg van de evolutie in de tijd van het vertegenwoordigde empirische domein en het ontstaan van nieuwe concepten waarmee geen rekening is gehouden (Figuur 2). Bijvoorbeeld: een integriteitstest voordat de gegevens in de hoofddatabase worden ingevoerd, ontdekt een formele anomalie. De behandeling van de anomalie (validatie of correctie) wordt opgeslagen in het ATMS (waardoor de anomalieën en de behandeling ervan in de tijd kunnen worden gevolgd, zoals verderop in dit artikel wordt aangegeven) en gevoed door een dashboard dat, door de monitoring van de anomalieën en de behandelingen, zal helpen bij het besluitvormingsproces met het oog op de verbetering van de gegevenskwaliteit.
Afhankelijk van de behoeften van de business wordt besloten deze anomalieën te beschouwen als:
- blokkerend: ze worden uit de database verwijderd op grond van de bovengenoemde ‘gesloten wereld’-hypothese;
- niet-blokkerend: de waarden worden nog steeds geïntegreerd in het informatiesysteem met de overeenkomstige record, om twee soorten redenen:
- door ze uit het systeem te weigeren zou het businessproces worden vertraagd (bv. de inning van sociale bijdragen) en ze worden niet als ‘strategisch’ beschouwd;
- ze moeten in het informatiesysteem in aanmerking worden genomen, omdat ze als strategisch worden beschouwd en verband houden met empirische gegevens waarvan de definitie kan evolueren. Vanaf een bepaalde drempel die door de specialisten op het terrein moet worden beoordeeld, vereist hun verwerking menselijke interpretatie, aangezien zij kunnen wijzen op het ontstaan van nieuwe verschijnselen waarmee in het informatiesysteem rekening moet worden gehouden (Figuur 2), door middel van versiebeheer. Bovendien zijn ze mogelijk afkomstig uit de stromen die de database voeden, een probleem dat, eenmaal geïdentificeerd, structureel kan worden opgelost met back tracking (Boydens, 2018, Boydens e.a., 2021).
De beslissing om ‘niet-blokkerende’ empirische anomalieën te identificeren is gevoelig, omdat ze gebaseerd is op voorspellende kennis van de realiteit die op een bepaald moment wordt verwerkt, wat zelf een evoluerend element is dat binnen het informatiesysteem onderhevig kan zijn aan gecoördineerde aanpassing. Dit brengt ons terug bij de epistemologische kwestie van de ‘hermeneutische lus’.
De hermeneutische benadering bestaat erin de empirische verschijnselen te beschouwen in termen van interacties in vergelijking met een eerder algemeen conceptueel kader dat is opgebouwd om er betekenis aan te geven. Elke interpretatieve benadering roept echter een paradox op: die van de ‘hermeneutische cirkel’ (Aron, 1969). Elke observatie heeft alleen zin wanneer ze wordt geconfronteerd met een geheel, met een ‘voorbegrip’. De semantiek van het geheel is echter zelf gebaseerd op de interpretatie van de samenstellende elementen. Het constructieproces dat de hermeneutiek impliceert, is van nature altijd onvolledig. Het is echter gepast om een weloverwogen stop te maken om voorlopige resultaten te leveren (Boydens, 1999).
Hoe kunnen ‘niet-blokkerende anomalieën’ en de behandeling ervan in aanmerking worden genomen zonder de prestaties of de integriteit van de gegevens in productie aan te tasten? Met het ATMS, ofwel Anomalies and Transactions Management System (Boydens e.a., 2021) – eventueel gekoppeld aan Data Quality Tools (Boydens e.a., 2021b) – in combinatie met Back Tracking (Boydens, 2018), gaan we van de ‘gesloten wereld’-hypothese naar die van een ‘open wereld’ onder geautomatiseerde controles binnen beheerdatabases. En daarbij wordt een geconsolideerd programma gebouwd om de datakwaliteit te beoordelen en structureel te verhelpen. Dit programma is nooit een ‘one shot’ omdat het in continuïteit moet worden uitgevoerd, inclusief een onderhoudsproces.
TOEPASSING OP MACHINE LEARNING: PERSPECTIEVEN
Voor het opzetten van de ML-cyclus
In het geval van machine learning (de Valeriola, 2020, Dierickx, 2019, 2022) kan het programma (analyse en bijbehorende oplossingen) – eerder in deze blogpost geschetst – stroomopwaarts worden toegepast op de gemobiliseerde gegevens om een voorspellend model te trainen en in de tijd te onderhouden voordat de ML-cyclus wordt geïmplementeerd.
De kern van de ML-cyclus (figuur 3)
In de kern van het ML-systeem kan men kwaliteitsindicatoren inbouwen die passen bij de gekozen ML-algoritmen en -modellen, bijvoorbeeld:
- annotaties die mogelijk via crowdsourcing zijn verkregen, in het geval van gesuperviseerde modellen (Northcutt e.a., 2021, Gupta e.a., 2021)
- de vertekeningen (of foutmarges) die al dan niet worden getolereerd, afhankelijk van de toepassingen die in synergie met IT en de business (ontwerpers van gegevens, gebruikers van het voorspellende model) worden bepaald.
Het in (Gupta e.a., 2021) aanbevolen systeem zou kunnen worden verrijkt door gebruik te maken van een ATMS aan de bron, zoals hierboven vermeld, en stelt ook voor in te spelen op de kwaliteit van reeds voor ML voorbewerkte gegevens.
Deze referentie illustreert het probleem van de slechte kwaliteit van gegevens binnen het ML-model. Zo kan een verkeerde verdeling van een kenmerk een vertekening inhouden die op haar beurt ethische kwesties oproept: in het geval van de risicogebaseerde beoordeling van kredietaanvragen, die in september 2022 door de EU wordt herzien:
“… algoritmen kunnen vertekeningen bevatten. Zo zal een model waarschijnlijk vaak krediet weigeren aan 30-jarigen en nooit aan 57-jarigen. Waarom? Simpelweg omdat er veel dossiers van 30-jarigen waren die de machine tijdens de training bekeek, zodat de kans om fouten te vinden groot was, terwijl er slechts één of twee voorbeelden waren van 57-jarige aanvragers en zij hun krediet telkens volledig betaalden (een echter zo ruwe fout dat ze meestal wordt voorkomen, maar andere afwijkingen kunnen schadelijker zijn).“
Figuur 3. Bron: Dierickx, 2022
Verklaarbaarheid van ML-voorspellingen: wetgeving, ethische en gegevenskwaliteitskwesties, nieuwe onderzoeksgebieden
In andere door de EU genoemde gevallen is de ondoorzichtigheid van deep learning-modellen zodanig dat zelfs ingenieurs geen precieze redenen meer kunnen geven voor de voorspellingen die daaruit voortvloeien.
Er wordt een wet voorbereid om te proberen de gebruikte procedures te reguleren, de AI Act, die de GDPR moet versterken. Met betrekking tot procedures naar analogie van kredietaanvragen menen deskundigen dat “Dit niet betekent dat de gegeven verklaringen zeker en vast zullen zijn (onmogelijk bij sommige modellen), maar dat ze zeer waarschijnlijk zullen zijn – sommige ingenieurs spreken inderdaad meer van interpreteerbaarheid dan van verklaarbaarheid.”
Het bovengenoemde programma (ATMS, data quality tools) vóór de ML-cyclus, gekoppeld aan de inrekeningname van een kwaliteitsbeoordeling in de kern van het ML-proces, wat allemaal gedocumenteerd moet worden, zou ook kunnen worden toegepast om gebruikers van voorspellende gegevens gerichter te informeren over de ‘verklaarbaarheid’ en de relatieve kwaliteit ervan, aangezien totale kwaliteit niet bestaat.
Er ontstaan geleidelijk nieuwe onderzoeksgebieden in deze richting:
Data Centric AI of ook Causal AI. Het probleem stelt zich dus stroomopwaarts, in de kern en stroomafwaarts van de gegevenslevenscyclus bij ML.
Wat ML betreft, zullen we in een later artikel laten zien hoe deze techniek de functionaliteiten van een ‘data quality tool’ kan verbeteren, bijvoorbeeld bij matchingoperaties, zoals aangekondigd in ons artikel van december 2021.
Referenties
Aron, R., 1969. La philosophie critique de l’histoire. 1969. Édition Librairie philosophique J. Vrin. Collection Points – Sciences humaines. ISBN 2560848158182.
Bade D., It’s about Time!: Temporal Aspects of Metadata Management in the Work of Isabelle Boydens. In Cataloging & Classification Quarterly (The International Observer), volume 49, n° 4, 2011, pp. 328-338. (lien vers l’article).
Boydens I., Informatique, normes et temps. Bruxelles : Bruylant, 1999, 570 p. (Cet ouvrage s’est vu décerner le prix de la Fondation L. Davin, conféré par l’Académie Royale des sciences, des lettres et des beaux-arts de Belgique, 1999). (Introduction et Première partie, pp. 30-126) – bibliothèques
Boydens I., “Strategic Issues Relating to Data Quality for E-government: Learning from an Approach Adopted in Belgium”. In Assar S., Boughzala I. et Boydens I., éds., “Practical Studies in E-Government : Best Practices from Around the World”, New York, Springer, 2011, p. 113-130 (chapitre 7).
Boydens I., Dix bonnes pratiques pour améliorer et maintenir la qualité des données. Bruxelles, Smals, Research Section, post de blog, 16/06/2014 (dernière mise à jour : décembre 2021). https://www.smalsresearch.be/dix-bonnes-pratiques-pour-ameliorer-et-maintenir-la-qualite-des-donnees/
Boydens I., « Data Quality & Back Tracking : depuis les premières expérimentations à la parution d’un Arrêté Royal ». Bruxelles, Smals, Research Section, post de blog, 14/05/2018.https://www.smalsresearch.be/data-quality-back-tracking-depuis-les-premieres-experimentations-a-la-parution-dun-arrete-royal/
Boydens I., Hamiti G. et Van Eeckhout R., Data Quality : “Anomalies & Transactions Management System” (ATMS), prototype & “work in progress”. Bruxelles, Smals, Research Section, post de blog, 8/12/2020.
Boydens I., Hamiti G. et Van Eeckhout R., Un service au cœur de la qualité des données. Présentation d’un prototype d’ATMS. In Le Courrier des statistiques, Paris, INSEE, juin-juillet 2021, n°6, p. 100-122.
https://www.insee.fr/fr/information/5398691?sommaire=5398695
Boydens I., Corbesier I. et Hamiti G., Data Quality Tools : retours d’expérience et nouveautés. Bruxelles, Smals, Research Section, post de blog, 07/12/2021. https://www.smalsresearch.be/data-quality-tools-retours-dexperience-et-nouveautes/
Brown S., Why it’s time for “data Centric Artificial Intelligence” ? MIT Management Sloan School, juin, 2022. https://mitsloan.mit.edu/ideas-made-to-matter/why-its-time-data-centric-artificial-intelligence
De Valeriola S., L’ordinateur au service du depouillement de sources historiques. ´ Eléments d’analyse semi-automatique d’un corpus diplomatique homogène. In Histoire & Mesure, 35, 2 (2020), 171–196.
De Valeriola, S. Can historians trust centrality ? Historical network analysis and centrality metrics robustness. In Journal of Historical Network Research 6 (2021), 45–85.
Dierickx L., « Apprentissage automatique : les challenges de la qualité des données dans la perspective d’une adéquation aux usages», Conférence, Groupe de contact FNRS « Analyse critique et amélioration de la qualité de l’information », ULB, mai 2022. https://mastic.ulb.ac.be/2022/02/reunion-du-groupe-de-contact-fnrs-analyse-critique-et-amelioration-de-la-qualite-de-linformation-numerique-%EF%BF%BC/
Dierickx, L. (2019, February). Why news automation fails. In Computation+ Journalism Symposium, Miami, FL.
Gupta N, Patel H, Afzal S, et al. (2021) Data Quality Toolkit: Automatic assessment of data
quality and remediation for machine learning datasets. arXiv [cs.LG]. Available at:
http://arxiv.org/abs/2108.05935.
Northcutt CG, Athalye A and Mueller J (2021) Pervasive label errors in test sets destabilize
machine learning benchmarks. arXiv [stat.ML]. Available at: http://arxiv.org/abs/2103.14749.
Redman T. C., If Your Data is Bad, your Machine Learning Tools are useless. Harvard, Business Review, avril 2018. https://hbr.org/2018/04/if-your-data-is-bad-your-machine-learning-tools-are-useless.
Sgaier S. et al., The Case for Causal AI, Stanford Innovation Social Review, summer 2020. https://ssir.org/articles/entry/the_case_for_causal_ai
Van Der Vlist, E. 2011. Relax NG. Mai 2011. Édition O’Reilly Media. ISBN: 0596004214
Dit is een ingezonden bijdrage van Isabelle Boydens, Data Quality Expert, Research Team en Gani Hamiti, Data Quality Analist, Databases Team. Dit artikel is geschreven onder hun eigen naam en heeft geen invloed op het standpunt van Smals. Het werd vertaald uit het Frans: Typologie des anomalies, un cadre pour l’action : le cas du machine learning.
Leave a Reply