Modèles de langue
Ces derniers mois, nous avons tous pu découvrir la puissance de l’IA générative, avec ChatGPT occupant le devant de la scène. À la base, il y a les modèles de langue larges (large language models – LLM): des réseaux neuronaux à grande échelle avec de nombreux paramètres entraînés à partir de grandes quantités de texte. Voici quelques applications de ces LLM :
- Générer un texte : pensez ainsi à un brouillon pour un mail ;
- Résumer un texte ;
- Traduire ;
- Classifier du texte ; cela inclut le ‘sentiment analysis’, comme la classification de commentaires de clients comme positifs ou négatifs ;
- Répondre à des questions ;
- Reconnaître des entités, telles que des noms de personnes ;
- Aider à écrire du code : voir l’article de blog sur De AI-Augmented Developer
Une application populaire est celle des réponses aux questions. Suite au lancement de ChatGPT, une masse d’outils permettant de répondre à des questions concernant votre propre contenu voient le jour. Le principe est très simple : téléchargez vos documents (PDF, Word, etc.) et vous pouvez presque immédiatement poser des questions, généralement dans un environnement de type “chatbot”.
Dans cet article, nous décrivons le fonctionnement d’un tel système de réponse aux questions et nous apportons quelques précisions sur la qualité que l’on peut attendre des résultats.
Question answering basé sur des modèles de langue
Le schéma ci-dessous présente les éléments qui composent un système de ‘question answering’ basé sur des modèles de langue. La partie supérieure (en bleu) représente toutes les étapes nécessaires à la préparation du contenu :
- Comme point de départ, nous avons une base de connaissance (knowledge base) composée d’un ou plusieurs documents. Il peut s’agir de différents formats comme PDF, Word ou des pages web. Dans cette première étape, le texte est extrait du document ;
- Le texte est ensuite divisé en de plus petits fragments (chunks) ;
- Ces fragments sont ensuite convertis en embeddings, une représentation numérique du texte qui permet de retrouver plus facilement des extraits de texte sémantiquement comparables ;
- Enfin, ces embeddings sont stockés dans une base de données vectorielles (vector store).
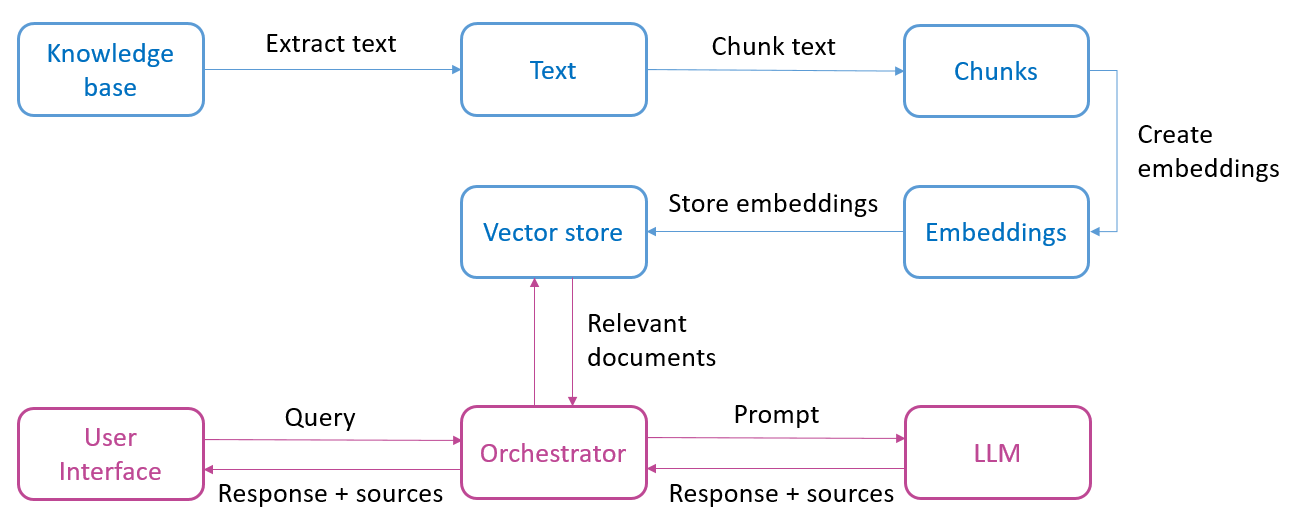
Après cette phase préparatoire, l’utilisateur final peut poser une question au système (voir la partie inférieure du schéma), celle-ci est ensuite traitée comme suit : la question de l’utilisateur (query) est convertie en embeddings, permettant de rechercher dans la base de données vectorielle (retrieval) les documents les plus proches sémantiquement de cette question. Ensuite, un prompt est envoyé au modèle de langue. Il contient toutes les informations nécessaires pour obtenir une réponse du modèle de langue: la question initiale de l’utilisateur, les documents pertinents trouvés et la mission spécifique (instruction) pour le modèle de langue. Enfin, nous obtenons une réponse générée, accompagnée d’une indication des sources (numéros de pages ou URL de sites web) si souhaité.
On peut se demander pourquoi ne pas immédiatement envoyer tous les documents de la base de connaissance au modèle de langue en tant que contexte. Il y a principalement deux raisons à cela. Premièrement, la taille du contexte que nous pouvons transmettre est limitée. Par exemple, le modèle populaire GPT-3.5-turbo est limité à 4000 tokens. Les tokens désignent la plus petite unité significative en laquelle un texte peut être divisé. Un token peut être un mot entier, mais aussi une partie de mot ou un signe de ponctuation, en fonction de la méthode de tokenization utilisée.
Une deuxième raison est le coût du recours à un modèle de langue large. En effet, il dépend du nombre de tokens en input et output. Ainsi, plus nous fournissons de contexte à l’input, plus le coût est élevé.
Frameworks
Les applications basées sur l’architecture ci-dessus peuvent être rapidement développées grâce à des frameworks comme Langchain. Ils offrent généralement des abstractions permettant d’exécuter en quelques lignes de code les tâches décrites dans le schéma ci-dessus (extraire le texte, le diviser, créer et sauvegarder les embeddings). Ils agissent également comme une sorte d’orchestrateur pour relier l’input de l’utilisateur à la base de données vectorielles et au modèle de langue.
En guise d’expérience, nous nous sommes lancé avec Langchain pour construire une application de question answering sur la base d’un PDF ou d’une page web. Avec la connaissance nécessaire du framework, la mise en place est très rapide.
Qualité du output
La principale question est bien sûr de savoir dans quelle mesure les réponses que nous recevons sont exactes. Nos expériences montrent que les réponses sont parfois impressionnantes : correctes, bien résumées et quelquefois accompagnées d’un raisonnement correct, par exemple pour interpréter si un montant de la question est supérieur ou inférieur à un montant limite.
Nous devons malheureusement aussi constater que les réponses sont souvent peu précises ou incomplètes, voire carrément fausses. Intuitivement, on pourrait penser que cela est intrinsèque à la nature générative des modèles linguistiques et au phénomène des hallucinations. Un facteur au moins aussi important est l’étape de retrieval : la recherche des fragments de texte les plus pertinents dans lesquels le modèle de langue doit trouver les informations pour composer une réponse. Si les informations utiles pour une réponse ne se trouvent pas dans les fragments de texte fournis, on ne peut pas s’attendre à ce que le modèle de langue renvoie une réponse exacte.
Indépendamment de ces failles, il existe un certain nombre de techniques permettant d’améliorer la qualité de l’output, notamment :
- Combiner le retrieval sémantique avec un retrieval lexical classique ;
- Inclure des sources pertinentes supplémentaires dans la base de connaissance ;
- Prompt engineering : adapter les instructions données au modèle de langue;
- L’ajustement de la taille des chunks et de la taille de du chevauchement entre les chunks. Nous notons ici que la limite du contexte des modèles de langue augmente. Ainsi, OpenAI fournit un modèle avec un contexte de 16 000 tokens. Cela permet d’inclure davantage de contexte. L’augmentation de la taille des chunks peut garantir que les informations sémantiquement liées restent plus longtemps dans un même chunk.
- Enfin, on peut également envisager d’affiner un modèle de langue, mais c’est beaucoup plus lourd.
Conclusion
Il serait bien de pouvoir mettre en place un système capable de répondre à des questions sur nos propres données avec un effort très limité. Cependant, la précision de la réponse reste un point d’attention important. Ce n’est pas pour rien que ces applications affichent invariablement un avertissement indiquant que les réponses peuvent être inexactes ou erronées et qu’il est toujours conseillé de vérifier le résultat.
Ce post est une contribution individuelle de Bert Vanhalst, IT consultant chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.
Leave a Reply