Deze blogpost past in het kader van onze studies omtrent knowledge graphs. In dit artikel zullen we het concept van virtual knowledge graphs toelichten, een techniek dat ons toelaat (relationele) databanken als een graaf te benaderen. Hoewel dit artikel hier en daar soms wat technisch en moeilijk wordt, geven we na voorbeelden duidelijke conclusies. Een lezer hoeft de voorbeelden (m.a.w. de “code”) dus niet door te nemen.
Een knowledge graph wordt gebouwd met data afkomstig uit verschillende bronnen, welke worden omgezet naar een graaf, waarna het geheel doorgaans in een graafdatabank wordt opgeslagen. Welke bronnen worden dan in een knowledge graph geïntegreerd? Voorbeelden van bronnen zijn bestaande (relationele) databanken die systemen ondersteunen, documenten (gescand en born-digital), en de kennis van personen. In dit artikel leggen we de nadruk op (relationele) databanken die bestaande systemen ondersteunen.
Heel wat bestaande systemen draaien bovenop (relationele) databanken. De informatie die in dergelijke systemen zit vervat is doorgaans moeilijk integreerbaar met andere bronnen die vereist zijn voor het bouwen van een knowledge graph. Of een organisatie kan bijvoorbeeld van mening zijn dat de bestaande systemen niet mogen vervangen worden door een graph databank, of wensen er niets aan te veranderen.
Het omzetten van data afkomstig uit een relationele databank (voor een specifiek doeleinde) naar een knowledge graph en deze in een graafdatabank opslaan leidt tot twee problemen: redundantie t.o.v. de originele data (en het beheer daarvan), en het bevragen van informatie dat mogelijks niet meer up-to-date is.
Een mogelijke oplossing hiervoor zijn virtual knowledge graphs. Virtual knowledge graphs laten toe om op een haast transparante manier de gegevens in een (relationele) databank als een graaf te benaderen. Achter de schermen zal zo’n systeem de bevragingen in een graph query-taal vertalen naar, bijvoorbeeld, SQL.
Mappings: relaties tussen een databank en een knowledge graph
Tijdens de omzetting van data naar een knowledge graph verplaatst het accent in de data van attributen naar dingen; een veldje stad met als inhoud “Brussel” wordt het concept van de stad Brussel met als naam “Brussel”, bijvoorbeeld. Dit aspect, dat gekend staat als “things, not strings”, maakt de graaf completer, expressiever, en meer betekenisvol dan de originele bronnen.
Om dit te realiseren, moeten we echter beschrijven hoe databanken zich tot de ontologie (vergelijkbaar met een schema) van een knowledge graph verhouden. Zulke beschrijvingen heten mappings en worden aan de hand van een speciaal taaltje beschreven. Een gestandardiseerd mapping taaltje is R2RML, wat staat voor RDB to RDF Mapping Language. R2RML werd in 2012 gepubliceerd en dient om gegevens in relationele databanken als RDF grafen te vertalen of te benaderen. RDF is een gestandaardiseerd graaf-datamodel en is een onderwerp dat we in een eerdere blog post hebben behandeld. RDF beschrijft dingen aan de hand van zogenaamde triples. Triples zijn van de vorm (subject, predicate, object) en verbinden een onderwerp (subject) met een voorwerp (object) aan de hand van een relatie (predicate). Een voorbeeld hiervan is: ex:Christophe ex:woontIn ex:Brussel.
Het voordeel van een standaard zoals R2RML is dat meerdere vrije en commerciële oplossingen deze ondersteunen, wat interoperabiliteit ten goede komt. Naast R2RML bestaan er andere taaltjes, maar in dit artikel leggen we het principe van virtual knowledge graphs aan de hand van R2RML uit. De oplossingen die we zullen aanhalen ondersteunen, naast R2RML, ook hun eigen taal.
Hoe gaat dit in zijn werk? Laten we vertrekken van een tabel Addresses met twee kolommen ID en city. Aan de hand van een mapping zullen we die tabel gebruiken om RDF triples te genereren. Een mapping bestaat uit:
- Exact 1 logische tabel (een query, tabel of view) die naar RDF zal worden vertaald. In dit geval alles uit de tabel
Addresses. - Exact 1 subject-map die de subject van onze triples zal genereren. In ons voorbeeld wordt de kolom
IDgebruikt om unieke IRI’s voor steden te creëren. Een subject-map kan ook 1 of meerdere referenties naar typen bevatten. In het voorbeeld is hier een verwijzing naardbpedia:Placedat voor elk subjectxde triplex rdf:type dbpedia:Placegaat genereren. - 0 of meedere predicate-object-maps die de overige predicaten en objecten zullen genereren. In ons voorbeeld nemen we de inhoud van de kolom
cityom een triple met predicaatfoaf:namete generen.
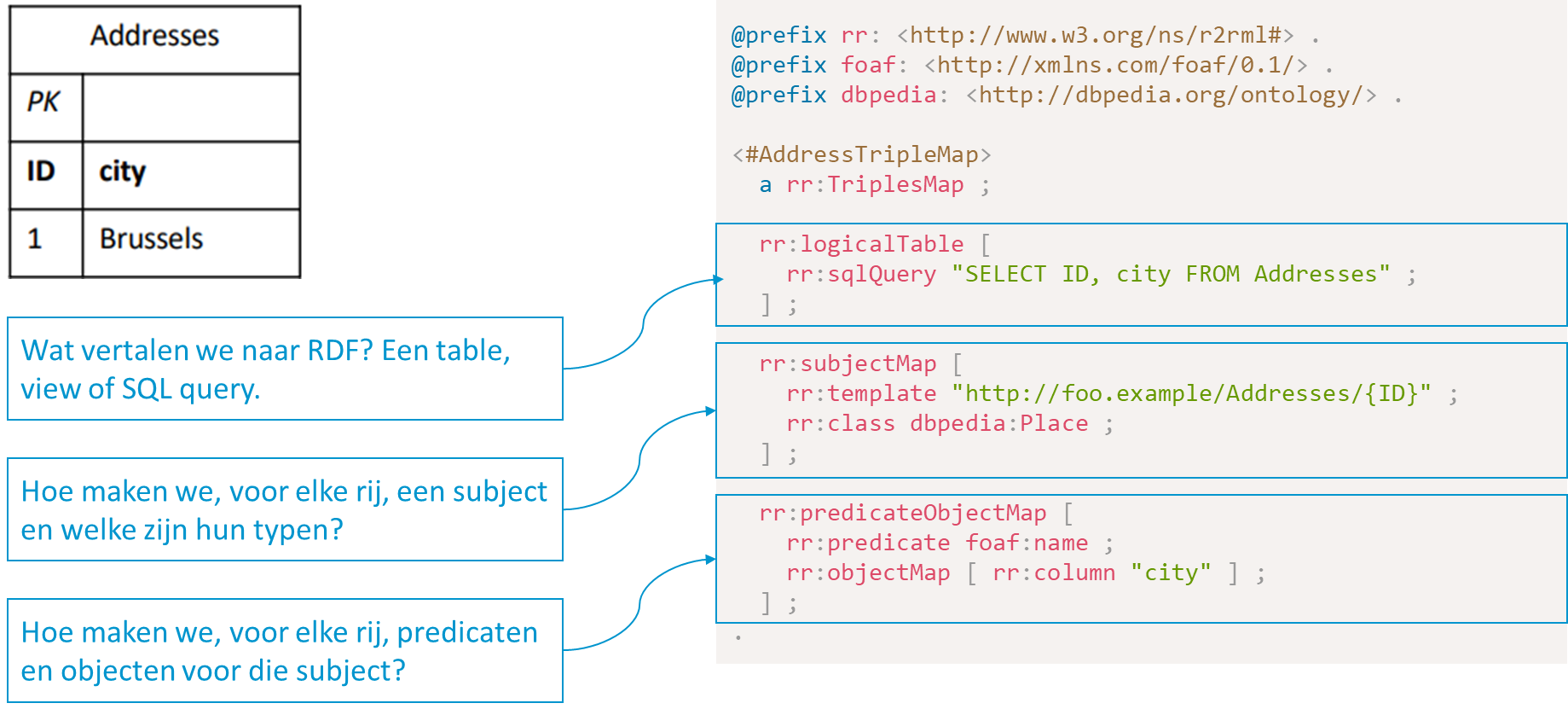
Aan de hand van deze mapping en het tabel in ons voorbeeld worden de volgende triples genereerd:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix dbpedia: <http://dbpedia.org/ontology/> .
<http://foo.example/Addresses/1>
a dbpedia:Place ;
foaf:name "Brussels" ;
.
R2RML laat ons ook toe om relaties tussen twee logische tabellen te declareren. Dit passen we toe in het volgende voorbeeld. We hebben een tabel People met drie kolommen (ID, fname, en addr). Er is een vreemde sleutel van People(addr) naar Addresses(ID). De logical table van deze mapping bevat de naam van de tabel en hierdoor worden alle kolommen geselecteerd. De subject-map maakt van elke subject een entiteit van het type foaf:Person. De predicate-object-map legt verbanden tussen de subjects van deze triplesmap met subjects van de voorgaande triplesmap aan de hand van een expliciete verwijzing (i.e., rr:parentTriplesMap) en de JOIN condities. Een R2RML processor zal de twee logische tabellen aan de hand van die condities JOINen. In ons voorbeeld resulteert dit in triples met de predicate foaf:based_near.
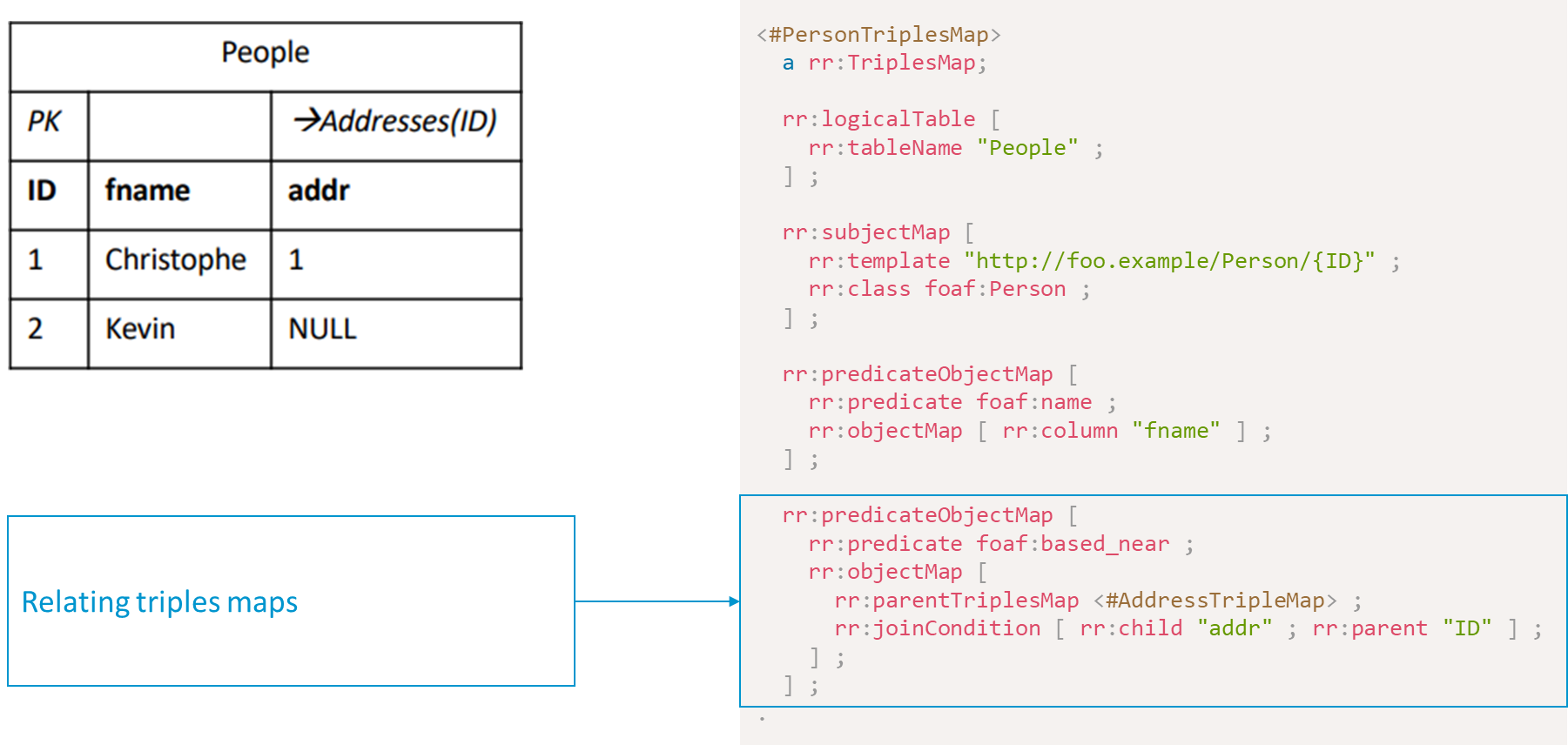
Nemen we de twee triplesmaps en de twee tabellen, dan kunnen we de volgende RDF graaf genereren:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix dbpedia: <http://dbpedia.org/ontology/> .
<http://foo.example/Addresses/1>
a dbpedia:Place ;
foaf:name "Brussels" ;
.
<http://foo.example/Person/1>
a foaf:Person ;
foaf:name "Christophe" ;
foaf:based_near <http://foo.example/Addresses/1> ;
.
<http://foo.example/Person/2>
a foaf:Person ;
foaf:name "Kevin" ;
. Merk op dat waar de vreemde sleutel tussen de twee tabellen initieel weinig betekenis had, de relatie tussen personen en plaatsen in de graaf expliciet wordt.
Relationele Databanken als RDF-grafen benaderen
R2RML mappings worden niet alleen gebruikt om RDF grafen uit relationele databanken te destilleren. In dit artikel worden de mappings gebruikt om de data in relationele databanken als RDF grafen te benaderen. Software zoals Ontop en Stardog vertalen bevragingen in SPARQL (de querytaal voor RDF) naar SQL.
We nemen als voorbeeld de volgende SPARQL-query:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT DISTINCT ?name WHERE {
?x foaf:name ?name .
}
Deze SPARQL-query vraagt naar alle unieke namen (via de predicaat foaf:name). Een virtuele knowledge graph analyseert de SPARQL-query en de mappings. De predicaat foaf:name wordt op twee plaatsen gebruikt (eens voor personen, en eens voor adressen). Aan de hand van die informatie herschrijft de virtual knowledge graph de SPARQL-query naar een SQL-query. Het antwoord op de SQL-query wordt dan gebruikt om een antwoord op de SPARQL-query te formuleren. Ontop, bijvoorbeeld, genereert de volgende SQL-query:
SELECT DISTINCT v5.Name2m2 AS Name2m2
FROM (
SELECT DISTINCT v1.fname AS Name2m2
FROM People v1 WHERE v1.fname IS NOT NULL
UNION ALL
SELECT DISTINCT v3.city AS Name2m2
FROM Addresses v3 WHERE v3.city IS NOT NULL
) v5
De SQL-query bevraagt de twee tabellen, verzamelt de resultaten van de twee bevragingen in een unie, en gebruikt de unie voor de uiteindelijke bevraging. Tools zoals Ontop zijn dus “intelligent” genoeg om zo min mogelijk informatie voor de query te gebruiken.
Het gaat zelfs een stapje verder: virtual knowledge graphs kunnen ook over de ontologieën die in de mappings werden gebruikt redeneren. Dit moet worden ingesteld en de ontologieën moeten beschikbaar worden gesteld (e.g., als input).
De virtual knowledge graphs gebruiken de axioma’s (type-hiërarchieën, rollen-hiërarchieën, etc.) in ontologiën om impliciete informatie uit expliciete informatie te halen. De mogelijkheden zijn doorgaans beperkt tot de reeds vermelde soorten axioma’s of axioma’s die tot de expressiviteit van relationele databanken behoren. Natuurlijk redeneren ze niet over de informatie op niveau van de graaf. De axioma’s worden gebruikt om de SQL-query’s als dusdanig te herschrijven.
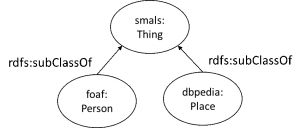
We illustreren dit met een voorbeeld. Laten we aannemen dat we in onze ontologie de volgende twee axioma’s hebben: alle entiteiten van het type foaf:Person zijn ook entiteiten van het type smals:Thing, en alle entiteiten van het type dbpedia:Place zijn ook entiteiten van het type smals:Thing. Die twee axioma’s laten ons toe om een eenvoudige klassenhiërarchie op te bouwen. We wijzigen onze mappings niet en vragen aan onze virtual knowledge graph: “Geef ons een lijst van alle dingen.”
PREFIX smals: <https://kg.smals.be/ontologies/smals#>
SELECT DISTINCT ?x WHERE {
?x a smals:Thing .
}
Wanneer de ontologie niet als input werd meegegeven, dan beschikken onze mappings niet over voldoende informatie om hier een antwoord op te geven. Ontop kan dus geen SQL-query genereren en geeft een leeg resultaat terug.
Wanneer we de ontologie expliciet als input meegeven, echter, dan wordt de volgende SQL-query gegenereerd om op bovenstaande SPARQL-query een antwoord te formuleren.
SELECT v9.ID1m1 AS ID1m1, v9.ID3m2 AS ID3m2, v9.v0 AS v0
FROM (
SELECT v3.ID1m1 AS ID1m1, NULL AS ID3m2, 0 AS v0
FROM (SELECT DISTINCT v1.ID AS ID1m1 FROM Addresses v1) v3
UNION ALL
SELECT NULL AS ID1m1, v7.ID3m2 AS ID3m2, 1 AS v0
FROM (SELECT DISTINCT v5.ID AS ID3m2 FROM People v5) v7
) v9
Ontop was in staat te achterhalen wat er allemaal met een smals:Thing overeenkwam en ging op zoek naar de corresponderende mappings. In dit voorbeeld had Ontop enkel nood aan de kolommen die voor de subjects van elke mapping werden gebruikt (zijnde ID van People en ID van Addresses). In de SQL-query zijn er dus twee kolommen die met deze twee ID’s overeenkomen, en een derde kolom voor de “boekhouding”; de waarde 0 voor Addresses en de waarde 1 voor People.
Virtual knowledge graphs vertalen SPARQL-query’s naar SQL-query’s die op hun beurt moeten verwerkt worden. Dit brengt ons naar enkele observaties:
- 1) Virtual knowledge graphs zijn, vergeleken met triplestores (graafdatabanken voor RDF), trager. De voordelen van virtual knowledge graphs zijn het bevragen van data in originele bronnen en het voorkomen van dataredundantie.
- 2) Het gebruik van ontologieën binnen de virtual knowledge graph laat ons toe meer informatie te bevragen, maar dit gaat natuurlijk ten koste van performantie. Men moet zich echter de vraag stellen of de voordelen zwaarder doorwegen dan de nadelen. Wensen we entiteiten via superklassen te benaderen, dan konden we deze ook expliciet in de mapping plaatsen.
Dat het ondersteunen van redeneren een negatieve impact op performantie heeft geldt ook voor triplestores. Voor virtual knowledge graphs moeten we echter rekening houden met het feit dat de resulterende SQL-query’s zeer complex kunnen zijn. Natuurlijk kunnen we ons voor een aantal problemen vrijwaren door de onderliggende databanken naargelang de vereisten te configureren (e.g., query timeout en max aantal JOINs).
Wanneer we van virtuele knowledge graphs gebruik maken, moeten we rekening houden met het feit dat niet alle SPARQL functionaliteit ondersteund kan worden. Sommige beperkingen hebben te maken met de onderliggende databank (de beschikbaarheid van REGEX-functionaliteit, bijvoorbeeld). Andere beperkingen hebben te maken met de manier hoe SPARQL-query’s naar SQL-query’s worden herschreven. Dit hangt af van de implementatie van de virtual knowledge graph.
Sommige beperkingen hebben mogelijks een belangrijke impact op het gebruik van de knowledge graph. De volgende SPARQL-query, bijvoorbeeld, vraagt naar alle leidinggevenden (+1, +2, …) van alle werknemers aan de hand van een zogenaamd arbitrair pad. Een arbitrair pad gaat op zoek naar 0-of-meerdere (*) of 1-of-meerdere (+) relaties tussen concepten van een bepaald patroon. In dit geval hebben we dus 1-of-meerdere smals:supervisor relaties tussen ?x en ?y.
PREFIX smals: <https://kg.smals.be/ontologies/smals#>
SELECT DISTINCT * WHERE {
?x smals:supervisor+ ?y.
}
Voor triplestores is dit een makkelijke query. Virtual knowledge graphs ondersteunen dit echter (nog) niet. Om dit te kunnen oplossen moeten we zelf onze SPARQL-query herschrijven. Als we weten dat er maximaal 4 lagen in de hiërarchie zijn, dan kunnen we deze exhaustief neerschrijven:
PREFIX smals: <https://kg.smals.be/ontologies/smals#>
SELECT DISTINCT * WHERE {
{ ?x smals:supervisor ?y } UNION # +1
{ ?x smals:supervisor/smals:supervisor ?y } UNION # +2
{ ?x smals:supervisor/smals:supervisor/smals:supervisor ?y } # +3
}
Dit vergt natuurlijk achtergrondkennis omtrent de graaf en een organisatie. Men zou kunnen denken dat dit op te lossen is aan de hand van de ontologie; namelijk door aan te geven dat smals:supervisor een transitieve relatie is. Op die manier zou men via ?x smals:supervisor ?y aan alle leidinggevenden van een persoon kunnen opvragen. Het probleem is dat transitiviteit niet tot de expressiviteit van courante virtual knowledge graph technologieën behoren. (*)
Dit brengt ons naar enkele nieuwe observaties:
- 3) Virtual knowledge graphs ondersteunen niet alle aspecten van SPARQL. Dergelijke beperkingen hebben als oorzaak de onderliggende relationele databank of de implementatie van de virtual knowledge graph.
- 4) Hoewel R2RML, de taal om relationele databanken naar RDF te vertalen, gestandaardiseerd is, is het gedrag van een virtual knowledge graph niet gestandaardiseerd. De beperkingen hangen af van de oplossing die men kiest (zie hier voor Ontop, en hier voor Stardog). De mappings zijn interoperabel, maar de oplossingen zijn dat niet.
- 5) De keuze van een oplossing hangt dus ook af van onze knowledge graph requirements.
Een laatste belangrijk punt is dat virtual knowledge graphs doorgaans aannemen dat de onderliggende relationele databases zich naar standaard SQL gedragen. Elke afwijking kan het proces verstoren. Dit hebben we zelf ondervonden toen we virtual knowledge graphs op een MS SQL Server database hebben toegepast. Een frappante beperking van MS SQL Server is dat deze geen LIMIT zonder ORDER BY toelaat, terwijl dit (hoewel te vermijden) eigenlijk mag. De SQL-query’s die virtual knowledge graphs genereren kunnen dan niet worden uitgevoerd, wat tot fouten leidt. Dit is spijtig, want een LIMIT zonder ORDER BY wordt door tal van graaf-exploratie tools, zoals Ontodia, gebruikt.
Een kleine studie
Binnen Smals Research hebben we virtual knowledge graphs toegepast op een MS SQL Server databank met informatie omtrent werknemers, softwareprojecten, hardware,… en hun relaties. Voor onze studie hebben we niet alleen een kleine ontologie, maar ook de nodige mappings in R2RML gemaakt. De mappings werden gebruikt om:
- RDF te genereren die in een triplestore werd opgeslagen aan de hand van Apache Jena (fuseki);
- Een Ontop installatie via Docker (ontop);
- Een Stardog installatie via Docker (stardog).
Voor de triplestore en Ontop hebben we ook omgevingen gecreëerd waar redeneren met de ontologie werd ingesteld (fuseki-r en ontop-r). Voor de triplestore hebben we RDFS redeneren ingesteld, en voor Ontop OWL QL. OWL reasoning in Apache Jena leidde tot problemen op een lokale machine (niet genoeg geheugen, want redeneren vergt resources). De triplestore draaide in een Docker omgeving op een standaard laptop. De MS SQL Server draaide op de infrastructuur van Smals. Dit is belangrijk om enige vertraging vanwege het netwerkverkeer in achting te nemen.
We hebben een aantal query’s geformuleerd die we op elk systeem 10-maal draaiden. Om cold-start problemen, zoals de eenmalige analyse van de mapping te vermijden, werd voor elk experiment een eenvoudige query eenmaal uitgevoerd. Hoewel niet extensief, diende dit experiment om een beter beeld te vormen van:
- welke de mogelijkheden van virtual knowledge graphs zijn, en
- welke de voor- en nadelen van bepaalde oplossingen zijn.
Query: een lijst van alle typen in de knowledge graph
Deze eenvoudige SPARQL-query laat ons toe om alle typen op te halen die in een is-een relatie werden gebruikt:
SELECT DISTINCT ?type WHERE {
[] a ?type .
} ORDER BY ?type
Uit de resultaten zien we dat een native triplestore sneller is, en dat is geen verrassing. Het inschakelen van redeneren heeft doorgaans een impact op de performantie. Voor deze query doet Stardog het beter dan Ontop.
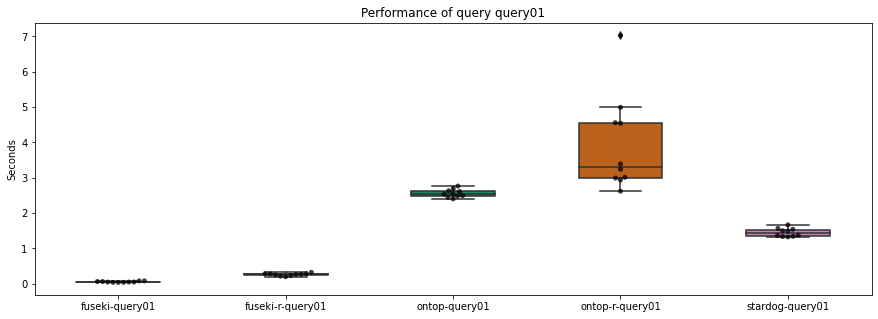
Query: een lijst van alle relaties in de knowledge graph
Deze eenvoudige SPARQL-query laat ons toe om alle relaties in de knowledge graph op te halen:
SELECT DISTINCT ?p WHERE {
[] ?p [] .
} ORDER BY ?p
Wat blijkt? Stardog was niet in staat deze query op te lossen. In sommige gevallen is Stardog niet in staat variabelen op de plaats van relaties te gebruiken als de subject en object niet elders gebruikt wordt of geen constanten bevat.
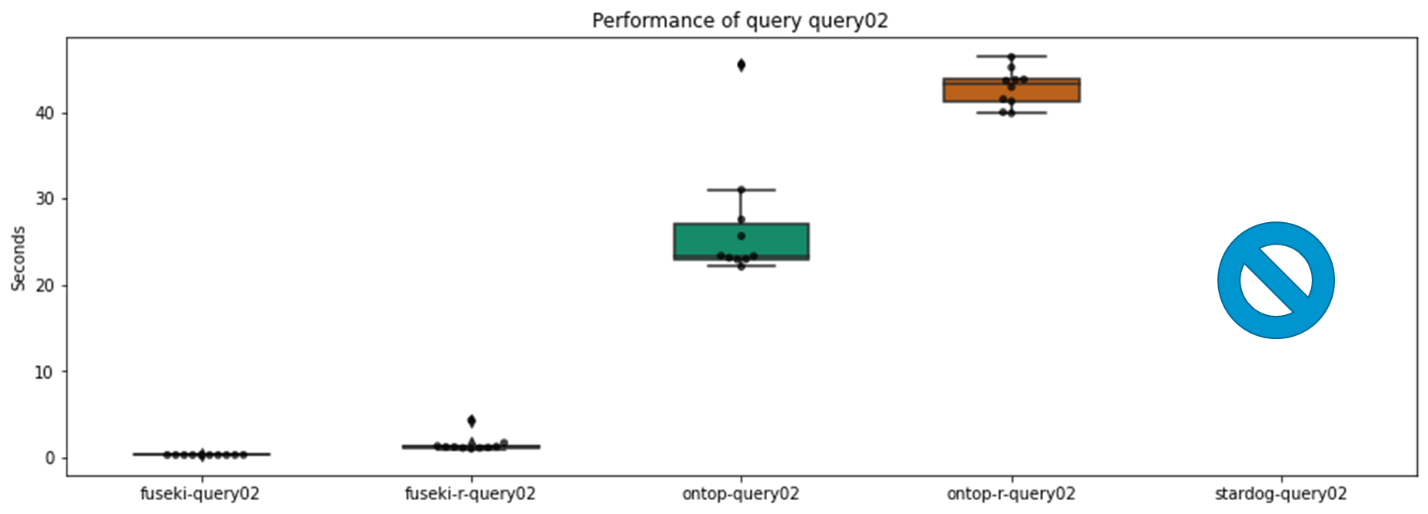
Query: een lijst van alle personen met namen, en hun optionele +2
De volgende SPARQL-query is een meer “realistische” query. We wensen een lijst van alle personen, hun namen (via rdfs:label), en hun +2 waar relevant (want niet iedereen heeft een +2). De OPTIONAL is vergelijkbaar met een LEFT OUTER JOIN in SQL.
SELECT DISTINCT ?p ?l ?s WHERE {
?p a smals:Person ; rdfs:label ?l .
OPTIONAL {
?p smals:supervisor [ smals:supervisor ?s ]
}
}
Ontop en Fuseki zonder reasoning hebben best gelijkaardige resultaten. Ook hier heeft redeneren een impact. Stardog is wat trager dan Ontop, maar toch ietsjes sneller dan Ontop met redeneren.
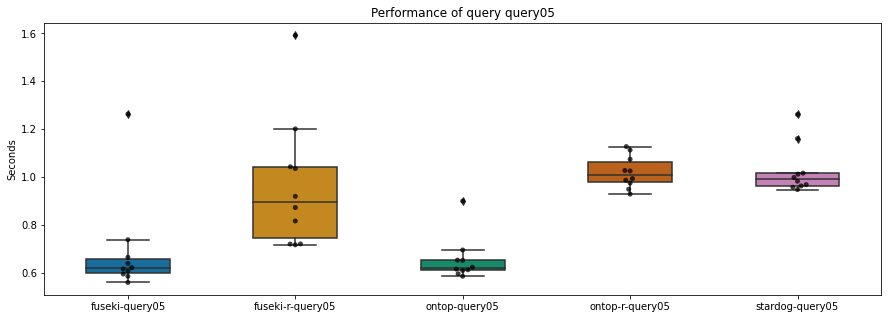
Query: een lijst van alle personen, hun eventuele naam, en zonder +1
Deze SPARQL-query lijkt op het vorige voorbeeld, maar heeft een belangrijk verschil; namelijk een OPTIONAL + ! BOUND. We zijn op zoek naar personen zonder +1 en bereiken dit door een OPTIONAL en enkel de resultaten te weerhouden waarvoor de variabele in de OPTIONAL geen waarde heeft (m.a.w.: “not bound”). Dit is een vrij courant patroon in SPARQL-query’s.
SELECT DISTINCT ?p ?l WHERE {
?p a smals:Person .
OPTIONAL { ?p rdfs:label ?l }
OPTIONAL { ?p smals:supervisor ?s. }
FILTER(!BOUND(?s))
}
Ook hier blijkt Ontop het beter te doen dan Stardog. En ook hier hebben Fuseki en Ontop gelijkaardige resultaten.
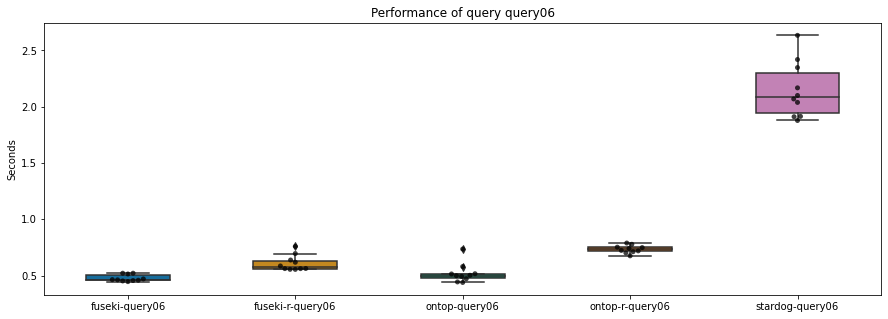
Vergelijking (**)
In onze studie blijkt Ontop het doorgaans (iets) beter te doen dan Stardog. Dat wil niet zeggen dat Stardog een slecht product is. Ontop is minder toegankelijk; alles werkt aan de hand van bestanden die geconfigureerd moeten worden. Stardog, daarentegen, biedt naast bestanden ook een studio-omgeving aan. Deze studio maakt het makkelijk om de (virtuele) knowledge graphs via een interface te beheren.
Ontop is een oplossing voor virtual knowledge graphs. Stardog, daarentegen, is ook een triplestore met (beperkte) BI functionaliteit. In Stardog kan men op een makkelijk wijze virtual knowledge graphs van verschillende databases met triplestores combineren. Omdat Ontop zich enkel tot virtual knowledge graph richt, is eenzelfde resultaat bekomen wat complexer. Het zal namelijk een combinatie van oplossingen vergen.
Waar Stardog makkelijk verschillende databanken (en databanktechnologieën) kan benaderen, moet men met Ontop hiervoor beroep doen op “middleware” zoals Dremio. Dremio is een platform dat ons toelaat bronnen als een virtuele dataset te benaderen. Met andere woorden; virtualisatie bovenop virtualisatie.
Zowel Ontop en Stardog hebben hun eigen taaltje naast de ondersteuning voor R2RML. De taal die Stardog aanbiedt is, tezamen met de studio omgeving, best wel gebruiksvriendelijker. Het gebruikt van dat taaltje gaat echter ten koste van interoperabiliteit. Verder is hun taaltje niet gebaseerd op een graaf-datamodel, waardoor we die niet als een graaf kunnen bevragen.
Opportuniteiten
Naast het bevragen van relationele databanken als een graaf, biedt het gebruik van virtual knowledge graphs en R2RML ook nog andere voordelen:
- De R2RML mappings zijn grafen, kunnen worden geannoteerd, en zelf als graaf bevraagd worden. In een complexe omgeving kunnen we dus nagaan waar informatie van entiteiten vandaan komt. Een SPARQL-query zoals “geef me alle mappings waar entiteiten van het type persoon worden gemaakt” zijn dus mogelijk.
- De gegevens in verschillende databanken zijn conceptueel geïntegreerd. Dit laat ons toe om geïntegreerde data op het niveau van knowledge graphs te valideren, bijvoorbeeld aan de hand van SHACL (het onderwerp van een vorig artikel).
Samenvatting
In dit artikel hebben we het onderwerp van virtuele knowledge graphs besproken. Virtual knowledge graphs laten ons toe om relationele databanken als een graaf te benaderen. Dit is handig als we wensen met de meest recente data te werken en data redundantie te reduceren. Daar tegenover staat dat virtual knowledge graphs wat trager zijn en niet alle mogelijkheden van de graaf-querytalen benut kunnen worden. De beperkingen van de virtual knowledge graphs liggen enerzijds aan de implementaties van oplossingen (m.a.w. vendor-specifieke beperkingen) en aan de onderliggende relationele databanken.
De meeste oplossingen ondersteunen een gestandaardiseerd taaltje om relationele databanken naar grafen af te beelden. Dit bevordert natuurlijk de interoperabiliteit. Het gedrag van een virtual knowledge graph is echter niet gestandaardiseerd en bestaande oplossingen moeten dus met de knowledge graph vereisten van een organisatie afgetoetst worden.
Voor dit artikel namen we enkel Ontop (vrije software) en Stardog (commercieel) onder de loep, maar er zijn natuurlijk ook nog andere oplossingen. De experimenten en vergelijkingen zijn beperkt en hadden de intentie om ons een aantal eerste inzichten te geven.
Indien up-to-date data belangrijk is en men met de best wel serieuze beperkingen (zoals het verlies in performantie, beperkingen in de soorten graafbevragingen die we kunnen stellen,…) kan leven, dan zijn virtual knowledge graphs een haalbare oplossing voor een organisatie.
Door de beperkingen heeft men ook geen garantie dat tools voor knowledge graphs zonder enige aanpassing naar behoren zullen werken. Ontodia, bijvoorbeeld, maakt “out-of-the-box” gebruik van arbitraire paden. Arbitraire paden worden voor virtual knowledge graphs doorgaans niet ondersteund. Men moet dus de instellingen van Ontodia aanpassen.
En indien men wenst om aan graph analytics te doen, waarbij men grote hoeveelheden data en hun relaties wil analyseren, dan zijn virtual knowledge graphs absoluut niet aan te raden, en moet men opteren voor een kopie in een performante graafdatabank. Dus: hoe intensiever de toepassingen bovenop de knowledge graph, hoe minder haalbaar virtual knowledge graphs.
(*) Ultrawrap van Capsenta bleek dit te ondersteunen. Capsenta werd echter door data.world overgenomen. Deze technologie hebben we voor deze studie niet getest.
(**) Stardog herschrijft mappings in R2RML naar hun eigen taaltje. Tijdens het schrijven van dit artikel werd het echter duidelijk dat een recentere versie deze niet correct vertaalde, waardoor de virtual knowledge graph niet de juiste antwoorden teruggaf. We hebben Stardog hieromtrent gecontacteerd.
_________________________
Dit is een ingezonden bijdrage van Christophe Debruyne, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.
Leave a Reply