In deze tweede blog over het Watson fenomeen gaan we dieper in op de systemen en tools die onder de noemer Watson Analytics beschikbaar zijn, hetzij in een test versie, hetzij in een commerciële versie. Gelet op het grote succes van de Watson computer die het kan opnemen tegen top concurrenten in de Quiz Jeopardy zijn de verwachtingen hoog gespannen, onder meer op het vlak van cognitive computing.
Meet the Watsons
Onder de noemer Watson is ondertussen een heel gamma systemen, tools en apps gelanceerd. Zo spreekt CIO magazine over niet minder dan 10 IBM Watson-powered Apps That Are Changing Our World en overlopen zij case-studies die zich afspelen in uiteenlopende maar zeer gespecialiseerde domeinen wat meteen duidelijk maakt dat er nog geen allesomvattend systeem bestaat die de verschillende functies verenigt. We pikken er een paar voorbeelden uit.
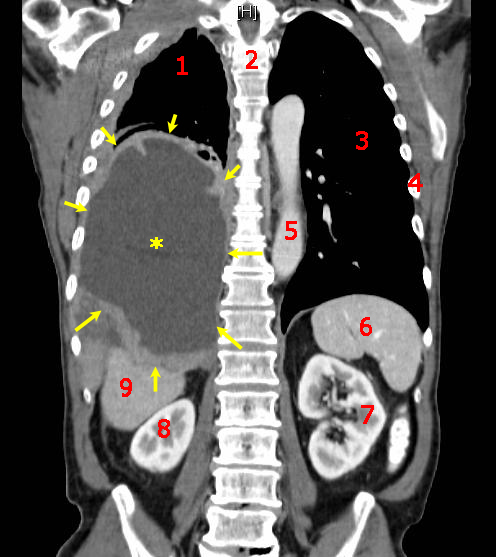
Interpretatie van een CT scan (GNU license – Stevenfruitsmaak)
In de oncologie … begeleidt Watson oncologen en huisartsen in het bepalen van de optimale therapeutische keuze. Dit is gebaseerd op het raadplegen van een omvangrijk corpus van richtlijnen, gepubliceerd onderzoek, gekende gevallen etc. en is dus een typisch expert systeem. De mate waarin deze informatie benaderd kan worden via vraagstelling in natural language lijkt minder relevant in deze setting en het is ook niet duidelijk in welke mate deze eigenschap aanwezig is in het systeem.
In het domein van de klinische studies… zou Watson kunnen ingezet kunnen worden voor het verzamelen en voorbereiden van de data. Dit is echter – terecht – een zeer strikt gereglementeerd domein waar uiterst hoge eisen gesteld worden zowel wat betreft de methodologie als de uitvoering van procedures. Bij twijfel over data-quality of de correcte uitvoering van een procedure komen typisch meerdere menselijke experten tussen om een oordeelkundige beslissing te nemen. Het lijkt me ondenkbaar dat een machine deze rol zou kunnen overnemen, maar het is anderzijds wel zo dat deze processen al in hoge mate door IT ondersteund zijn.
Watson als e-mail voorproever … een app die sentiment analyse doet op draft e-mail berichten die door de gebruiker ingetikt werden, welke gebruikt zou kunnen worden door wie onzeker is over de beoogde ondertoon van het bericht (buiten het lijstje van CIO magazine).
Maar wat is nu precies die cognitive computing aanpak waarmee Watson zich wil onderscheiden van traditionele technologieën ?
Cognitive computing
Het classificeren van bomen als cognitive taak
Bij IBM Research spreekt men over computer systemen die kunnen leren en op een natuurlijke manier interageren met de mens en aldus een aanvulling bieden op wat, hetzij de mens alleen, hetzij de machine alleen zouden kunnen doen. Dergelijke systemen helpen menselijke experten betere beslissingen te nemen dank zij de toegang tot Big Data. Onder de noemer op een natuurlijke manier interageren kan men natuurlijk meerdere dingen verstaan en dit hoeft dus niet per se te verwijzen naar een spraakgestuurd systeem.
Wikipedia maakt ons niet veel wijzer: cognitive computing maakt een nieuwe klasse van problemen berekenbaar, en richt zich op complexe situaties die gekenmerkt worden door ambiguïteit en onzekerheid; met andere woorden, het behandelt problemen van een “menselijke soort”. Het artikel werd gelabeld door de wikipedia gemeenschap in verband met multiple issues (persoonlijke opinie, belangenconflict) en er werd gesuggereerd dat het zou moeten vallen onder de term artificiële intelligentie.
“When it comes to neural networks, we don’t entirely know how they work…. And what’s amazing is that we’re starting to build systems we can’t fully understand … ”, aldus Jerome Pesenti (vice president of the Watson team at IBM) op The Platform.
Is het feit dat we niet volledig begrijpen hoe het system werkt dan een garantie dat het werkt ? Laten we eventjes terug de voeten op de grond zetten.
Watson Analytics
De best gekende Watson voor het grote publiek lijkt vooralsnog het Watson Analytics systeem te zijn dat gebruikers toelaat zijn eigen (op te laden) datasets of beschikbare voorbeeld datasets te analyseren in de cloud.
In de gratis trial versie van Watson zitten 4 modules, waarvan twee voor analytics (Explore en Predict), één voor eenvoudige transformaties op de data (Refine) en één voor reporting (Assemble). Met Explore kan men opgeladen datasets exploreren, hetzij door textuele vragen te stellen, hetzij door gebruik te maken van de voorstellen die Watson zelf doet. Het idee van cognitive computing is hier wel degelijk aanwezig. Met de module Predict kan men vragen een predictief model op te stellen om een op te geven target variabele te verklaren en dus bijvoorbeeld te weten te komen welke factoren een verkoopscijfer kunnen verklaren in een sales dataset.
The proof of the pudding is in the eating: Explore
Volgens de documentatie van IBM bevat de trial versie reeds de belangrijkste functionaliteiten (uitgenomen toegang tot Twitter data, uitgebreide connectiviteit en capaciteit voor grote datasets).
Een aantal ervaringen en bevindingen met de tool (zonder volledig te willen zijn):
- Vragen voorgesteld of begrepen door Watson zijn noodzakelijk in het Engels en in een min of meer gestandardiseerd formaat, bijvoorbeeld What is the trend of Sales in Thousands over Week by Market Size ?
- Watson valt dus terug op standaardconstructies zoals bijvoorbeeld een breakdown van aantallen over de categorieën van één of meerdere criteria, of bijvoorbeeld een trend van een grootheid over een tijdsdimensie. Mits een tijdsdimensie herkend werd…
- Opdat Watson de betekenis van een gegeven goed zou kunnen interpreteren moet dit in het bronbestand zinvol (in het engels) gelabeld zijn, zoniet moet dat manueel gebeuren. Zo herkent Watson via de naam week een tijdsgegeven en interpreteert hij een naam sales als een volume. Men mag er echter niet van uit gaan dat dit altijd automatisch correct zal gebeuren.
- Men mag niet blindelings vertrouwen op de voorstellen van Watson. Zo is het zinvol de som te maken van salesvolumes over de verschillende filialen van elke regio, maar moet men eerder het gemiddelde nemen als men bijvoorbeeld het inkomen van de inwoners van zo’n regio wil beschrijven.
- Domeinkennis en zorgvuldige interpretatie zijn dus belangrijk.
De vraag stelt zich dan tot welk soort gebruiker men zich richt. De ervaren analyst zal zich allicht snel ergeren aan voorstellen die niet relevant zijn en snel uitgekeken zijn op de beperkte mogelijkheden qua visualisatie en modellering, terwijl een leek in data-analyse misschien niet kritisch genoeg staat ten overstaan van automatisch gegenereerde resultaten.
The proof of the pudding is in the eating: Predict
Om Predict te testen gebruiken we best gekende of gesimuleerde datasets waar een specifiek model in zit dat Watson er dan uit moet kunnen halen. In een eerste voorbeeld, rond werkloosheid, werden twee datasets voorbereid met als targetvariable het feit of een werkloze binnen een bepaalde tijd werk vindt of niet (uitstroom), samen met twee persoonskenmerken: regio en inkomen (in vorige betrekking). In dataset1 wordt de uitstroom puur toevallig bepaald, in dataset2 is er een systematisch verband tussen uitstroom en de twee verklarende variabelen volgens een logistische regressie. Enkele vaststellingen:
- Bij het exploreren weigert Watson mijn vraag om uitstroom te modelleren en stelt hij voor om het aantal regio’s te tellen voor elk niveau van uitstroom wat veel minder relevant is.
- Bij de eerste dataset worden geen predictors gevonden, bij de tweede vindt Watson slechts een zwak verband met inkomen. Hij vergeet dus de regio als predictor en het sterke verband. Eén van de problemen lijkt hier te zijn dat de gegevens over inkomen in klassen ingedeeld werden terwijl het model een eenvoudige continue modellering vereist.
Ook in een ander voorbeeld slaagde Watson er niet in een mooi lineair model met twee predictoren er uit te halen. Slechts één van beide werd gevonden. Het lijkt er dus op dat Watson niet sterk genoeg is om zelfs eenvoudige en duidelijke statistische modellen te ontdekken en teruggrijpt naar automatische maar rudimentaire technieken.
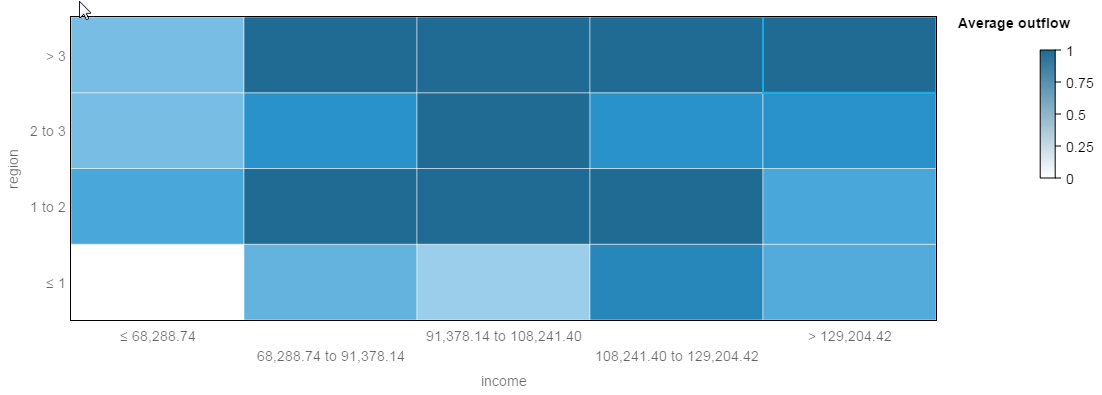
Screenshot van Watson Analytics (gesimuleerde dataset).
Conclusies
Het jongere broertje van de Watson machine lijkt nog niet volwassen. Dat is geen schande omdat de problemen die men wil aanpakken van een dergelijke complexiteit zijn dat de technologie er niet klaar voor is en men moet zich bovendien ook vragen stellen over de theoretische haalbaarheid. Watson kan ongetwijfeld wél een rol spelen als tool voor exploratie en visualisatie.
Mijn opinie is dat IBM moet opletten voor het creëren van te hoog gespannen verwachtingen en de daarmee gepaard gaande teleurstelling van de klanten.
Leave a Reply